The Autocorrelation Function (ACF) of a time series \(Y_t\) relates sequential correlations (on the y-axis) \(\rho_k = \rho(Y_t, Y_{t-k})\) for \(k = 1, 2, …, K\) to the time lag \(k\) (on the x-axis). Often this is presented in graphical form because it allows to quickly detect patterns that are typical of the dynamical properties of the underlying time series. Note that the time lag \(k\) is sometimes called the “order” of autocorrelation.
The sample autocorrelations are computed by the formula
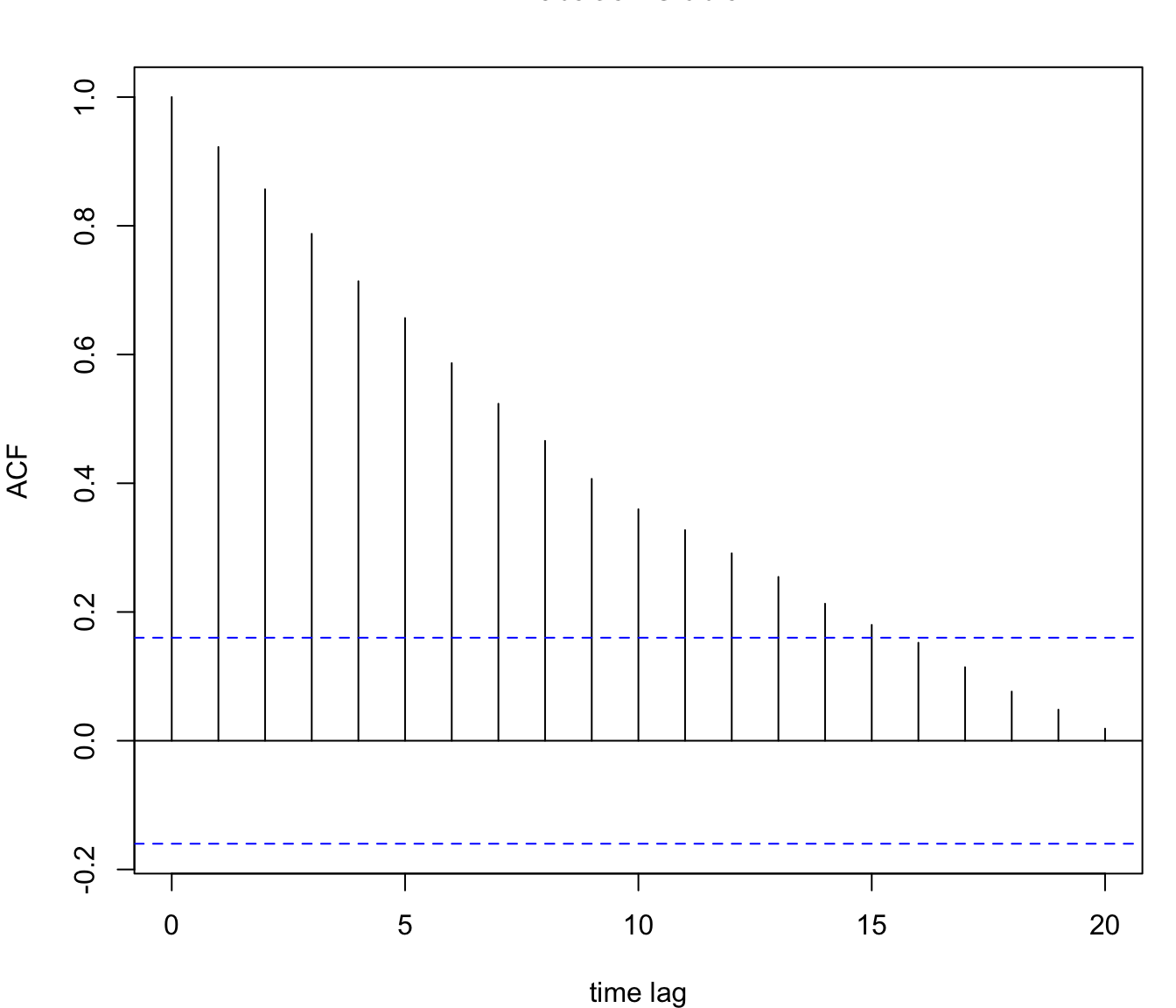
The 95% Confidence Intervals (of individual autocorrelation coefficients) are displayed as two horizontal lines, based on the approximated standard deviation \(\sigma_{\rho_k} \simeq \tfrac{1}{\sqrt{T}}\)(Bartlett 1946). These bands assume a white-noise null hypothesis (approximately i.i.d. observations/residuals); if that assumption is violated, they are only approximate and may be anti-conservative.
The Partial Autocorrelation Function (PACF) at lag \(k\) is the correlation between \(Y_t\) and \(Y_{t-k}\) after removing the linear effects of the intermediate lags \(Y_{t-1},\ldots,Y_{t-k+1}\). In practice, PACF isolates the direct lag-\(k\) relationship that is not explained by shorter lags.
92.1.1 Horizontal axis
The horizontal axis displays the time lag \(k\).
92.1.2 Vertical axis
The vertical axis represents the autocorrelation coefficients \(\hat{\rho}_k\).
92.2 R Module
92.2.1 Public website
The (Partial) Autocorrelation Function is available on the public website:
To compute the (Partial) Autocorrelation Function, the R code uses the standard acf and pacf functions to compute the analysis.
92.3 Purpose
In practice the ACF can be used to:
describe/summarize autocorrelation at various orders
identify non-seasonal and seasonal trends
identify various types of typical patterns that correspond to well-known forecasting models
check the independence assumption of the residuals of regression and forecasting models
92.4 Pros & Cons
92.4.1 Pros
The (Partial) Autocorrelation Function has the following advantages:
It is relatively easy to interpret and provide a lot of information about the serial correlation of a time series.
It can be computed with many software packages (even though one should be careful when using spreadsheets because they do not take empty cells that occur in lagged time series into account properly).
The combination of Partial and (ordinary) Autocorrelation Functions allows one to identify how the time series model should be specified (Box and Jenkins 1970).
It allows one to check an important assumption of residuals (prediction errors).
92.4.2 Cons
The (Partial) Autocorrelation Function has the following disadvantages:
It is sensitive to outliers.
The confidence intervals are not always computed correctly in statistical software. There are (at least) two types of confidence intervals: one for testing whether residuals contain autocorrelation1 and another which should be used to identify the autocorrelation structure of the time series model2.
92.5 Example
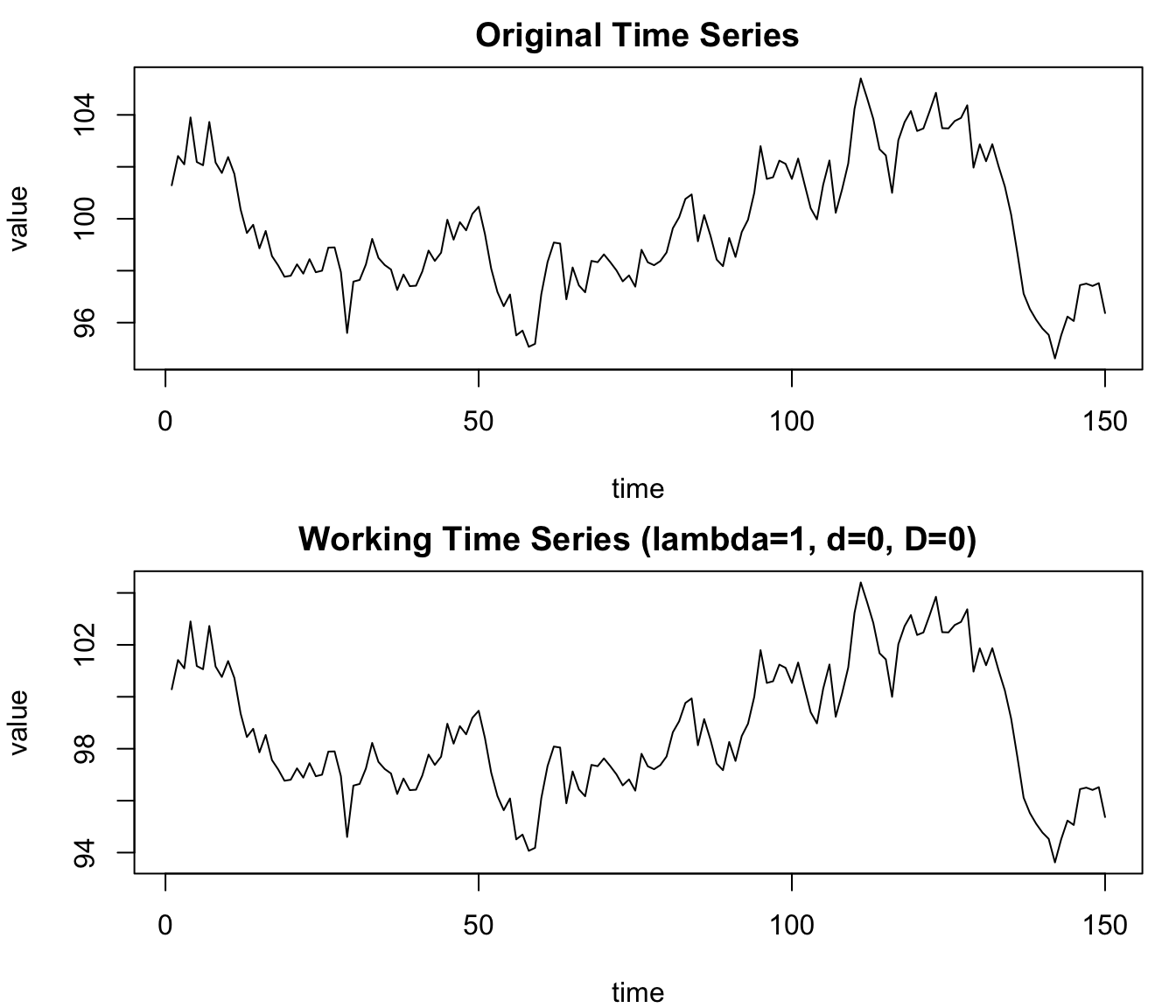
Let us consider the Airline Data and apply the ACF analysis. In a first stage we compute the ACF without any differencing, i.e. \(d = D = 0\) (these parameters were introduced in Section 91.1). The analysis shows the ACF for the original time series and exhibits a pattern which is typical for time series with a non-seasonal trend and strong seasonality:
The coefficients of the ACF are positive and slowly decreasing.
The seasonal coefficients, i.e. \(\rho_{12}, \rho_{24}, \rho_{36}, ...\) are positive and slowly decreasing too.
In the next step we set \(d = 1\) in order to apply non-seasonal differencing (the other parameter is not changed, \(D = 0\)). When we recompute the ACF (with \(d=1\)) then an entirely different pattern is observed, as is shown in the R module where the long-run trend pattern has disappeared. Only the seasonal Autocorrelation coefficients are still clearly positive and slowly decreasing, indicating the presence of a strong, seasonal pattern.
Finally we set \(d = D = 1\) to apply ordinary and seasonal differencing before recomputing the ACF. The R module shows that the combined differencing procedures eliminate the trend and the seasonal pattern. We can see this in the ACF because it does not exhibit the typical seasonality pattern anymore.
In later chapters, this information will be used to build a practical forecasting model for the Airline time series.
92.6 Task
Based on the ACF, examine the monthly time series of Divorces and determine whether or not there is a long-run trend and seasonality.
Bartlett, M. S. 1946. “On the Theoretical Specification and Sampling Properties of Autocorrelated Time-Series.”Journal of the Royal Statistical Society. Series B (Methodological) 8 (1): 27–41.
Box, George E. P., and Gwilym M. Jenkins. 1970. Time Series Analysis: Forecasting and Control. San Francisco: Holden-Day.
In this case you should set the field “CI type” equal to “White Noise” in the R module.↩︎
This is achieved by setting the field “CI type” to the value “MA”↩︎