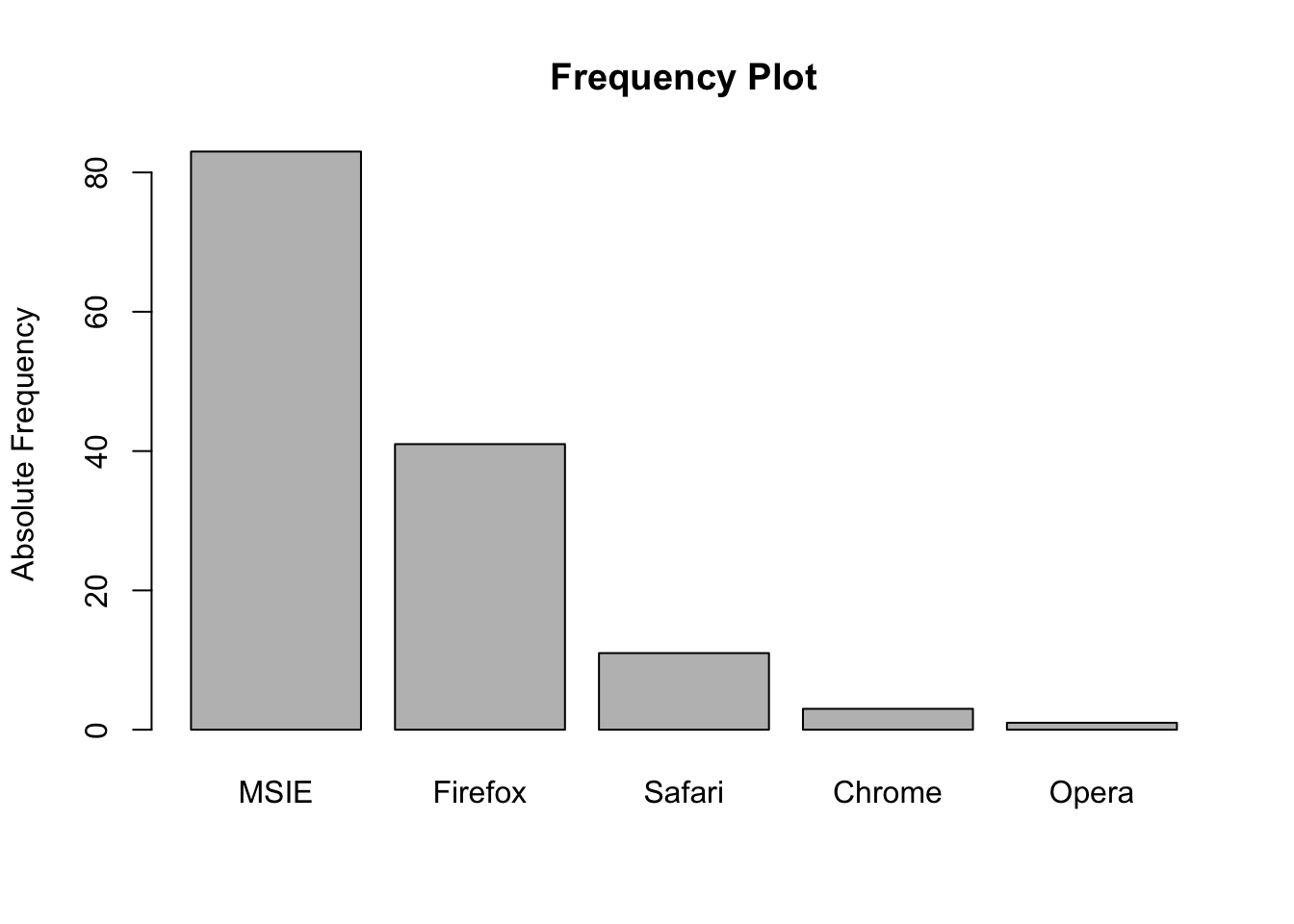
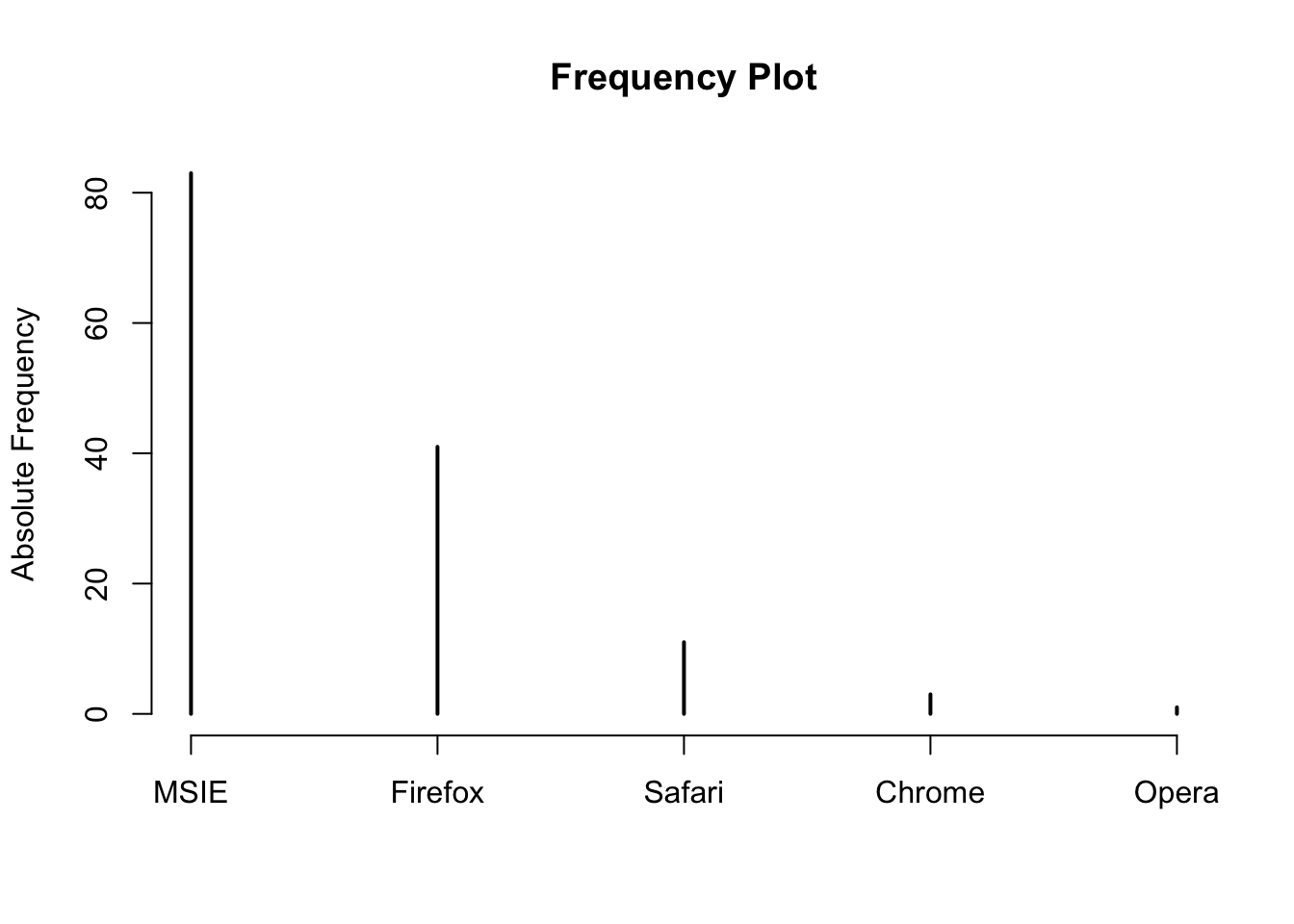
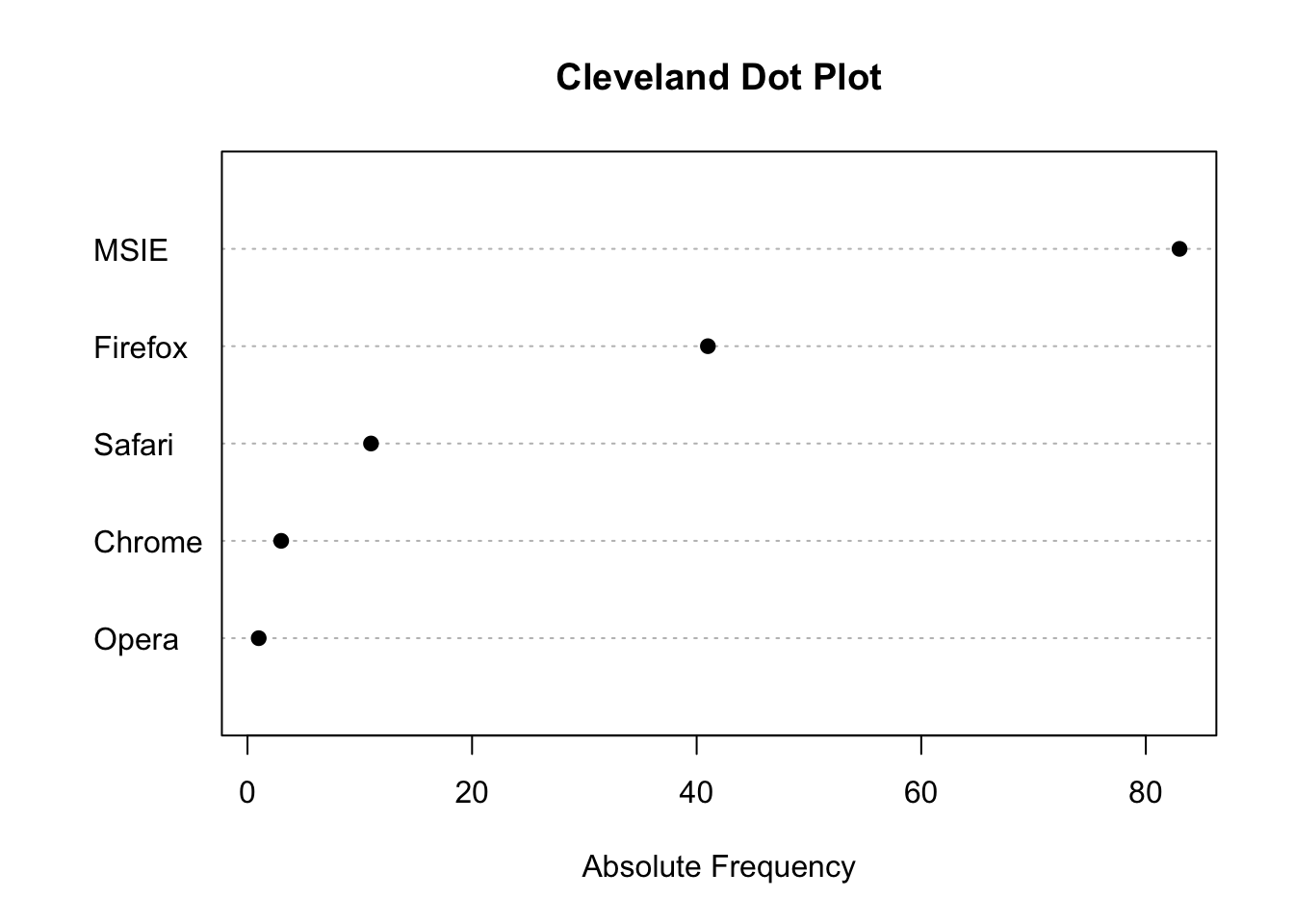
x <- c('Firefox','MSIE','MSIE','MSIE','MSIE','Firefox','Firefox','MSIE','Chrome','Firefox','Firefox','MSIE','MSIE','MSIE','MSIE','MSIE','Firefox','MSIE','Firefox','Firefox','MSIE','Firefox','Firefox','MSIE','MSIE','Firefox','Firefox','Safari','MSIE','Firefox','MSIE','MSIE','MSIE','Firefox','MSIE','MSIE','Firefox','MSIE','MSIE','MSIE','Firefox','MSIE','MSIE','Firefox','Opera','Firefox','MSIE','MSIE','MSIE','Firefox','Firefox','Safari','Firefox','Firefox','MSIE','MSIE','MSIE','Firefox','Safari','MSIE','MSIE','MSIE','MSIE','Firefox','MSIE','Chrome','MSIE','Firefox','Safari','Safari','Firefox','MSIE','MSIE','Firefox','MSIE','MSIE','MSIE','MSIE','Firefox','MSIE','MSIE','MSIE','MSIE','Firefox','MSIE','Firefox','Safari','Firefox','MSIE','MSIE','MSIE','MSIE','MSIE','MSIE','MSIE','Safari','Firefox','MSIE','Firefox','MSIE','MSIE','MSIE','MSIE','MSIE','Firefox','MSIE','Firefox','MSIE','MSIE','MSIE','Firefox','MSIE','MSIE','MSIE','Safari','MSIE','Firefox','Firefox','MSIE','Safari','Safari','Firefox','MSIE','MSIE','MSIE','MSIE','Chrome','MSIE','Firefox','MSIE','MSIE','MSIE','MSIE','Firefox','Safari','MSIE','MSIE','MSIE','MSIE')
par2 = 'grey'
mytab <- sort(table(x),T)
barplot(mytab, col = par2, main = "Frequency Plot", xlab = "", ylab = 'Absolute Frequency')