library(boot)
library(psych)
boot.stat <- function(s,i) {
s.mean <- mean(s[i])
s.median <- median(s[i])
s.midrange <- (max(s[i]) + min(s[i])) / 2
s.hmean <- harmonic.mean(s[i])
s.gmean <- geometric.mean(s[i])
c(s.mean, s.median, s.midrange, s.hmean, s.gmean)
}
x <- runif(n = 150, min = 10, max = 50)
par1 <- 200 # number of simulations
par2 <- 5 # significant digits
r <- boot(x, boot.stat, R = par1, stype = "i")
z <- data.frame(cbind(r$t[,1],r$t[,2],r$t[,3],r$t[,4],r$t[,5]))
colnames(z) <- list("mean","median","midrange","harmonic","geometric")
myq.1 <- 0.005
myq.2 <- 0.025
myq.3 <- 0.975
myq.4 <- 0.995
df = data.frame(statistic = c("mean",
"median",
"midrange",
"harmonic",
"geometric"),
P0.5 = c(signif(quantile(r$t[,1],myq.1)[[1]], par2),
signif(quantile(r$t[,2],myq.1)[[1]], par2),
signif(quantile(r$t[,3],myq.1)[[1]], par2),
signif(quantile(r$t[,4],myq.1)[[1]], par2),
signif(quantile(r$t[,5],myq.1)[[1]], par2)
),
P2.5 = c(signif(quantile(r$t[,1],myq.2)[[1]], par2),
signif(quantile(r$t[,2],myq.2)[[1]], par2),
signif(quantile(r$t[,3],myq.2)[[1]], par2),
signif(quantile(r$t[,4],myq.2)[[1]], par2),
signif(quantile(r$t[,5],myq.2)[[1]], par2)
),
Q1 = c(signif(quantile(r$t[,1],0.25)[[1]], par2),
signif(quantile(r$t[,2],0.25)[[1]], par2),
signif(quantile(r$t[,3],0.25)[[1]], par2),
signif(quantile(r$t[,4],0.25)[[1]], par2),
signif(quantile(r$t[,5],0.25)[[1]], par2)
),
Estimate = c(signif(r$t0[1], par2),
signif(r$t0[2], par2),
signif(r$t0[3], par2),
signif(r$t0[4], par2),
signif(r$t0[5], par2)
),
Q3 = c(signif(quantile(r$t[,1],0.75)[[1]], par2),
signif(quantile(r$t[,2],0.75)[[1]], par2),
signif(quantile(r$t[,3],0.75)[[1]], par2),
signif(quantile(r$t[,4],0.75)[[1]], par2),
signif(quantile(r$t[,5],0.75)[[1]], par2)
),
P97.5 = c(signif(quantile(r$t[,1],myq.3)[[1]], par2),
signif(quantile(r$t[,2],myq.3)[[1]], par2),
signif(quantile(r$t[,3],myq.3)[[1]], par2),
signif(quantile(r$t[,4],myq.3)[[1]], par2),
signif(quantile(r$t[,5],myq.3)[[1]], par2)
),
P99.5 = c(signif(quantile(r$t[,1],myq.4)[[1]], par2),
signif(quantile(r$t[,2],myq.4)[[1]], par2),
signif(quantile(r$t[,3],myq.4)[[1]], par2),
signif(quantile(r$t[,4],myq.4)[[1]], par2),
signif(quantile(r$t[,5],myq.4)[[1]], par2)
),
SD = c(signif(sd(r$t[,1]), par2),
signif(sd(r$t[,2]), par2),
signif(sd(r$t[,3]), par2),
signif(sd(r$t[,4]), par2),
signif(sd(r$t[,5]), par2)
),
IQR = c(signif(quantile(r$t[,1],0.75)[[1]] - quantile(r$t[,1],0.25)[[1]], par2),
signif(quantile(r$t[,2],0.75)[[1]] - quantile(r$t[,2],0.25)[[1]], par2),
signif(quantile(r$t[,3],0.75)[[1]] - quantile(r$t[,3],0.25)[[1]], par2),
signif(quantile(r$t[,4],0.75)[[1]] - quantile(r$t[,4],0.25)[[1]], par2),
signif(quantile(r$t[,5],0.75)[[1]] - quantile(r$t[,5],0.25)[[1]], par2)
)
)
print(df)
op <- par(mfrow=c(2,3))
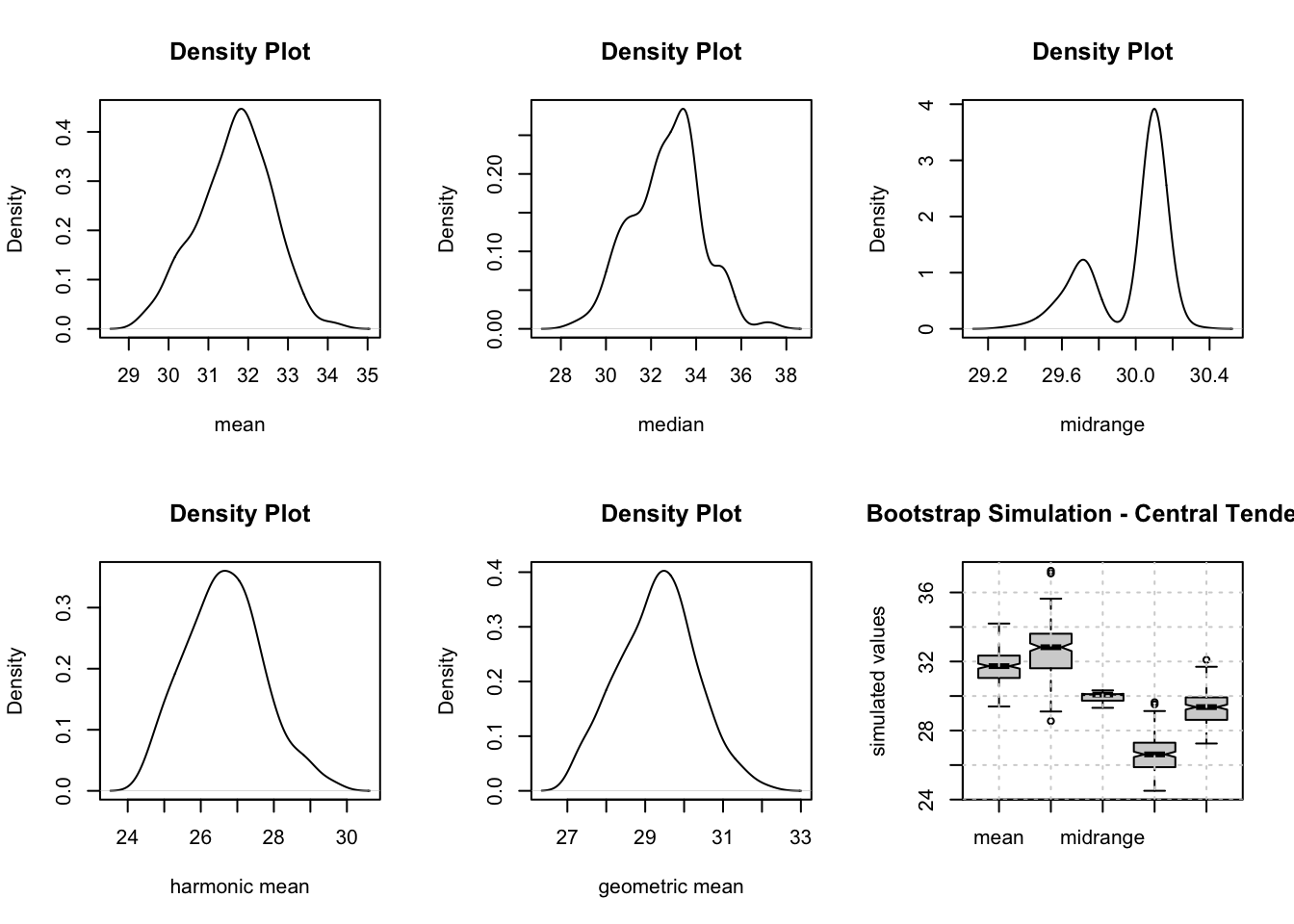
plot(density(r$t[,1]),main="Density Plot",xlab="mean")
plot(density(r$t[,2]),main="Density Plot",xlab="median")
plot(density(r$t[,3]),main="Density Plot",xlab="midrange")
plot(density(r$t[,4]),main="Density Plot",xlab="harmonic mean")
plot(density(r$t[,5]),main="Density Plot",xlab="geometric mean")
colnames(z) = c("mean", "median", "midrange", "harmonic", "geometric")
boxplot(z,notch=TRUE,ylab="simulated values",main="Bootstrap Simulation - Central Tendency")
grid()