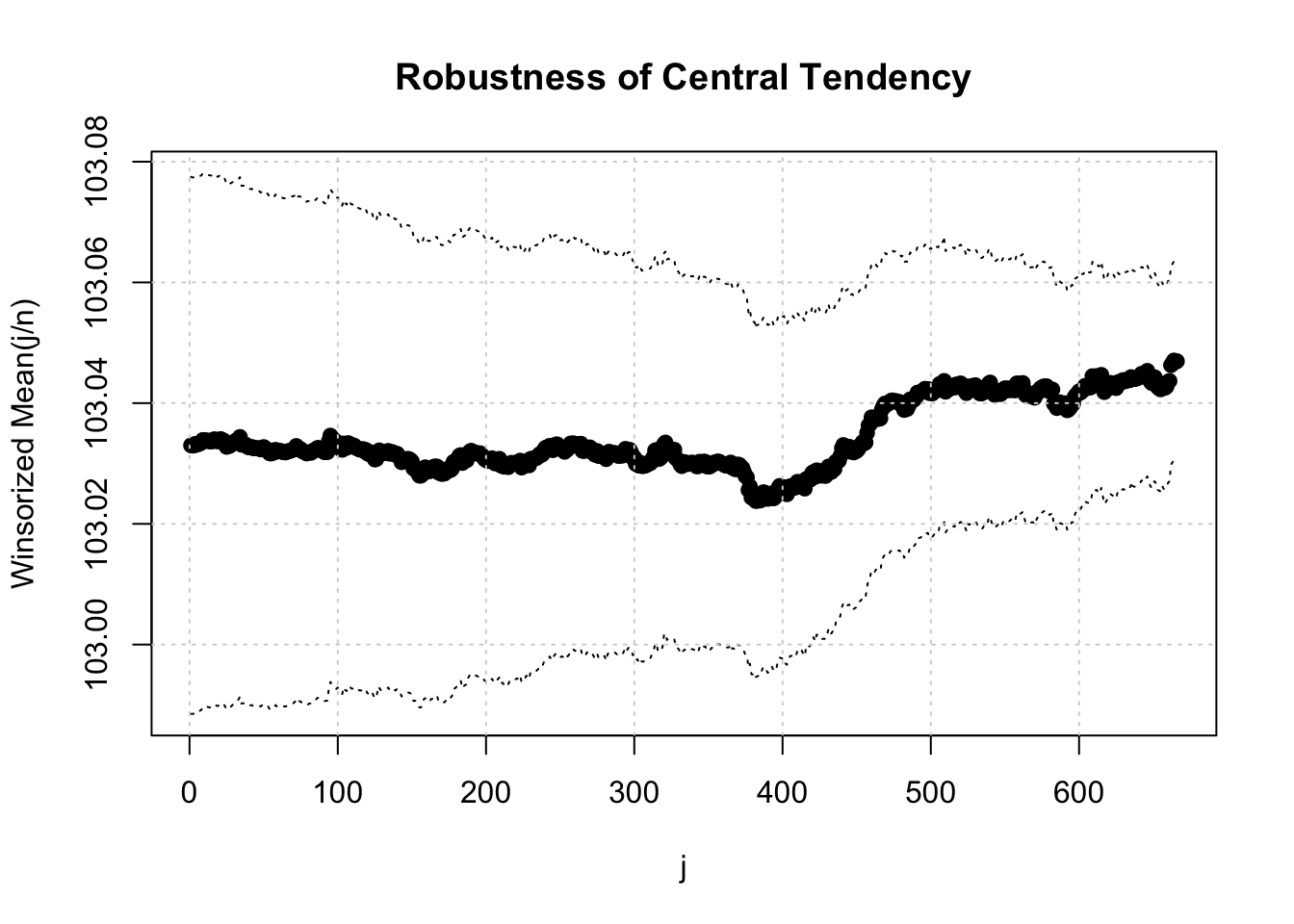
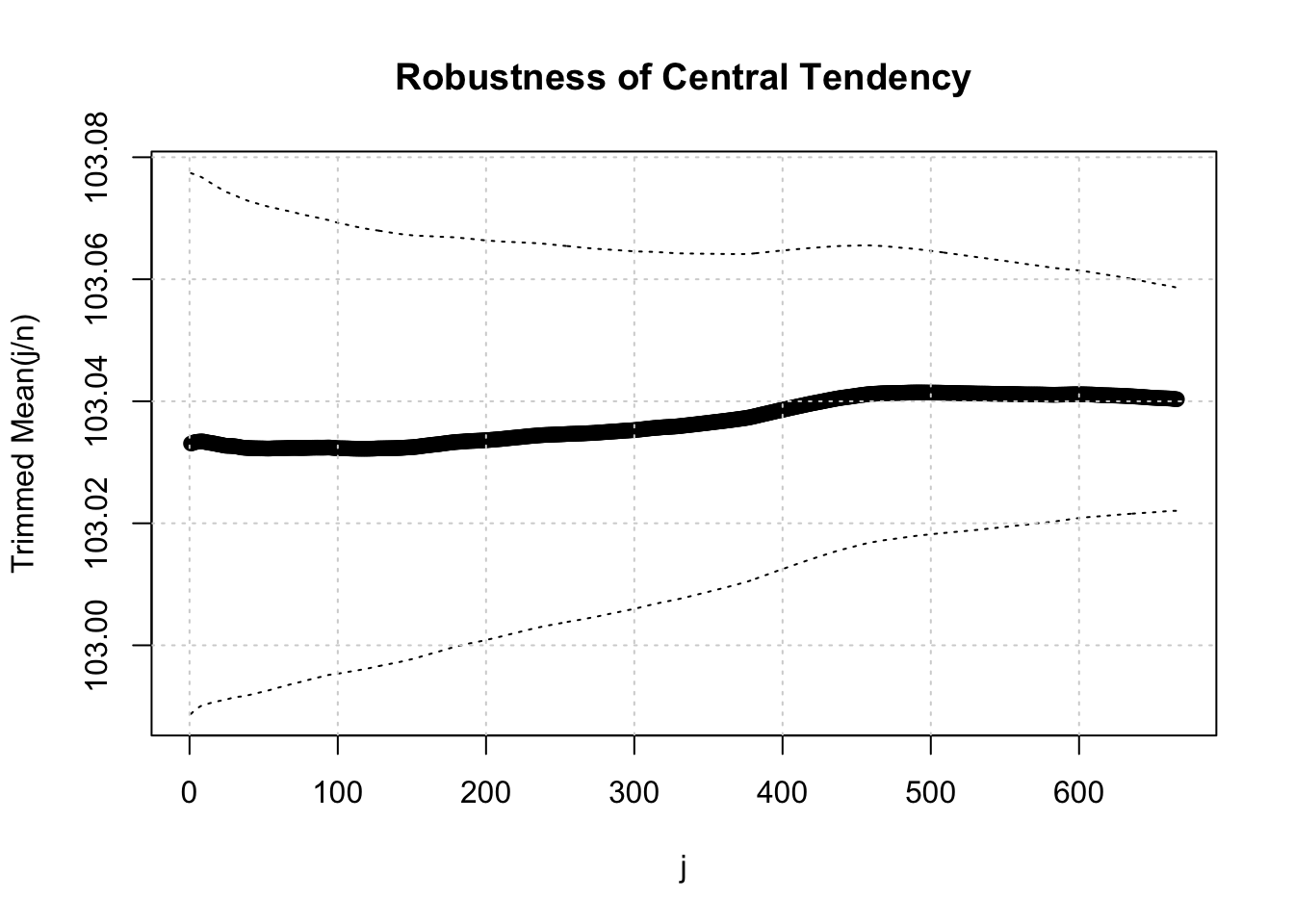
x <- rnorm(2000, 3, 1) + 100
main = 'Robustness of Central Tendency'
geomean <- function(x) {
return(exp(mean(log(x))))
}
harmean <- function(x) {
return(1/mean(1/x))
}
quamean <- function(x) {
return(sqrt(mean(x*x)))
}
winmean <- function(x) {
x <-sort(x[!is.na(x)])
n<-length(x)
denom <- 3
nodenom <- n/denom
if (nodenom>40) denom <- n/40
sqrtn = sqrt(n)
roundnodenom = floor(nodenom)
win <- array(NA,dim=c(roundnodenom,2))
for (j in 1:roundnodenom) {
win[j,1] <- (j*x[j+1]+sum(x[(j+1):(n-j)])+j*x[n-j])/n
win[j,2] <- sd(c(rep(x[j+1],j),x[(j+1):(n-j)],rep(x[n-j],j)))/sqrtn
}
return(win)
}
trimean <- function(x) {
x <-sort(x[!is.na(x)])
n<-length(x)
denom <- 3
nodenom <- n/denom
if (nodenom>40) denom <- n/40
sqrtn = sqrt(n)
roundnodenom = floor(nodenom)
tri <- array(NA,dim=c(roundnodenom,2))
for (j in 1:roundnodenom) {
tri[j,1] <- mean(x,trim=j/n)
tri[j,2] <- sd(x[(j+1):(n-j)]) / sqrt(n-j*2)
}
return(tri)
}
midrange <- function(x) {
return((max(x)+min(x))/2)
}
q1 <- function(data,n,p,i,f) {
np <- n*p;
i <<- floor(np)
f <<- np - i
qvalue <- (1-f)*data[i] + f*data[i+1]
}
q2 <- function(data,n,p,i,f) {
np <- (n+1)*p
i <<- floor(np)
f <<- np - i
qvalue <- (1-f)*data[i] + f*data[i+1]
}
q3 <- function(data,n,p,i,f) {
np <- n*p
i <<- floor(np)
f <<- np - i
if (f==0) {
qvalue <- data[i]
} else {
qvalue <- data[i+1]
}
}
q4 <- function(data,n,p,i,f) {
np <- n*p
i <<- floor(np)
f <<- np - i
if (f==0) {
qvalue <- (data[i]+data[i+1])/2
} else {
qvalue <- data[i+1]
}
}
q5 <- function(data,n,p,i,f) {
np <- (n-1)*p
i <<- floor(np)
f <<- np - i
if (f==0) {
qvalue <- data[i+1]
} else {
qvalue <- data[i+1] + f*(data[i+2]-data[i+1])
}
}
q6 <- function(data,n,p,i,f) {
np <- n*p+0.5
i <<- floor(np)
f <<- np - i
qvalue <- data[i]
}
q7 <- function(data,n,p,i,f) {
np <- (n+1)*p
i <<- floor(np)
f <<- np - i
if (f==0) {
qvalue <- data[i]
} else {
qvalue <- (1-f)*data[i] + f*data[i+1]
}
}
q8 <- function(data,n,p,i,f) {
np <- (n+1)*p
i <<- floor(np)
f <<- np - i
if (f==0) {
qvalue <- data[i]
} else {
if (f == 0.5) {
qvalue <- (data[i]+data[i+1])/2
} else {
if (f < 0.5) {
qvalue <- data[i]
} else {
qvalue <- data[i+1]
}
}
}
}
midmean <- function(x,def) {
x <-sort(x[!is.na(x)])
n<-length(x)
if (def==1) {
qvalue1 <- q1(x,n,0.25,i,f)
qvalue3 <- q1(x,n,0.75,i,f)
}
if (def==2) {
qvalue1 <- q2(x,n,0.25,i,f)
qvalue3 <- q2(x,n,0.75,i,f)
}
if (def==3) {
qvalue1 <- q3(x,n,0.25,i,f)
qvalue3 <- q3(x,n,0.75,i,f)
}
if (def==4) {
qvalue1 <- q4(x,n,0.25,i,f)
qvalue3 <- q4(x,n,0.75,i,f)
}
if (def==5) {
qvalue1 <- q5(x,n,0.25,i,f)
qvalue3 <- q5(x,n,0.75,i,f)
}
if (def==6) {
qvalue1 <- q6(x,n,0.25,i,f)
qvalue3 <- q6(x,n,0.75,i,f)
}
if (def==7) {
qvalue1 <- q7(x,n,0.25,i,f)
qvalue3 <- q7(x,n,0.75,i,f)
}
if (def==8) {
qvalue1 <- q8(x,n,0.25,i,f)
qvalue3 <- q8(x,n,0.75,i,f)
}
midm <- 0
myn <- 0
roundno4 <- round(n/4)
round3no4 <- round(3*n/4)
for (i in 1:n) {
if ((x[i]>=qvalue1) & (x[i]<=qvalue3)){
midm = midm + x[i]
myn = myn + 1
}
}
midm = midm / myn
return(midm)
}
midm <- array(NA,dim=8)
for (j in 1:8) midm[j] <- midmean(x,j) #Midmean for various types of quantiles
win <- winmean(x)
tri <- trimean(x)
df = data.frame(Statistic = c("Arithmetic Mean",
"SD of Arithmetic Mean",
"t-value",
"Geometric Mean",
"Harmonic Mean",
"Quadratic Mean",
"Median",
"Midrange",
"Midmean for various quartiles (def 1)",
"Midmean for various quartiles (def 2)",
"Midmean for various quartiles (def 3)",
"Midmean for various quartiles (def 4)",
"Midmean for various quartiles (def 5)",
"Midmean for various quartiles (def 6)",
"Midmean for various quartiles (def 7)",
"Midmean for various quartiles (def 8)"),
Value = c(arm <- mean(x),
armse <- sd(x) / sqrt(length(x)),
arm / armse,
geomean(x),
harmean(x),
quamean(x),
median(x),
midrange(x),
midm[1],
midm[2],
midm[3],
midm[4],
midm[5],
midm[6],
midm[7],
midm[8]))
print(df)