141Leaf Diagnostics for Conditional Inference Trees
141.1 Definition
Leaf diagnostics extend the Conditional Inference Tree workflow (Chapter 140) by evaluating the distribution of a continuous outcome inside each terminal node (leaf).
Instead of reading only leaf means or predicted values, this approach inspects:
center,
spread,
tail behavior,
and distributional fit quality
within each predicted segment.
141.2 Why This Matters
In regression settings, two leaves can have similar average predictions but very different reliability characteristics. For leaf \(\ell\) with outcome \(Y\):
\[
\mathrm{Var}(Y\mid \ell)
\]
may differ strongly across leaves. This is evidence of conditional variance heterogeneity (a heteroskedasticity-like pattern in the prediction structure).
141.3 Practical Workflow
Fit a ctree with a continuous outcome.
Use terminal nodes as panels.
Compare leaf-wise quantiles, variability, and shape diagnostics.
Flag leaves with high spread, strong skewness, or heavy tails.
Communicate predictions with leaf-specific reliability comments.
For predictive interpretation, this diagnostic should preferably be repeated on a holdout/test sample.
141.4 R Module
141.4.1 Public website
Leaf diagnostics are available through the Conditional EDA app in Tree mode:
In RFC, open “Descriptive / Conditional EDA”, switch to Tree mode, select a continuous outcome, and choose exogenous variables for the ctree split structure.
141.5 Example: Regression Leaves for Maximum Heart Rate
The example below models maxheartrateNum using ageNum and thalassemiaLabel, then compares leaf diagnostics panel-by-panel.
The embedded app uses the heart dataset. The short R example below uses synthetic data so that the same leaf-diagnostics logic can be reproduced directly in code.
141.6 A Minimal R Example of Leaf-Wise Summaries
The same idea can be demonstrated without the app. The code below fits a simple regression tree, records the terminal node for each observation, and then summarizes the response distribution within each leaf.
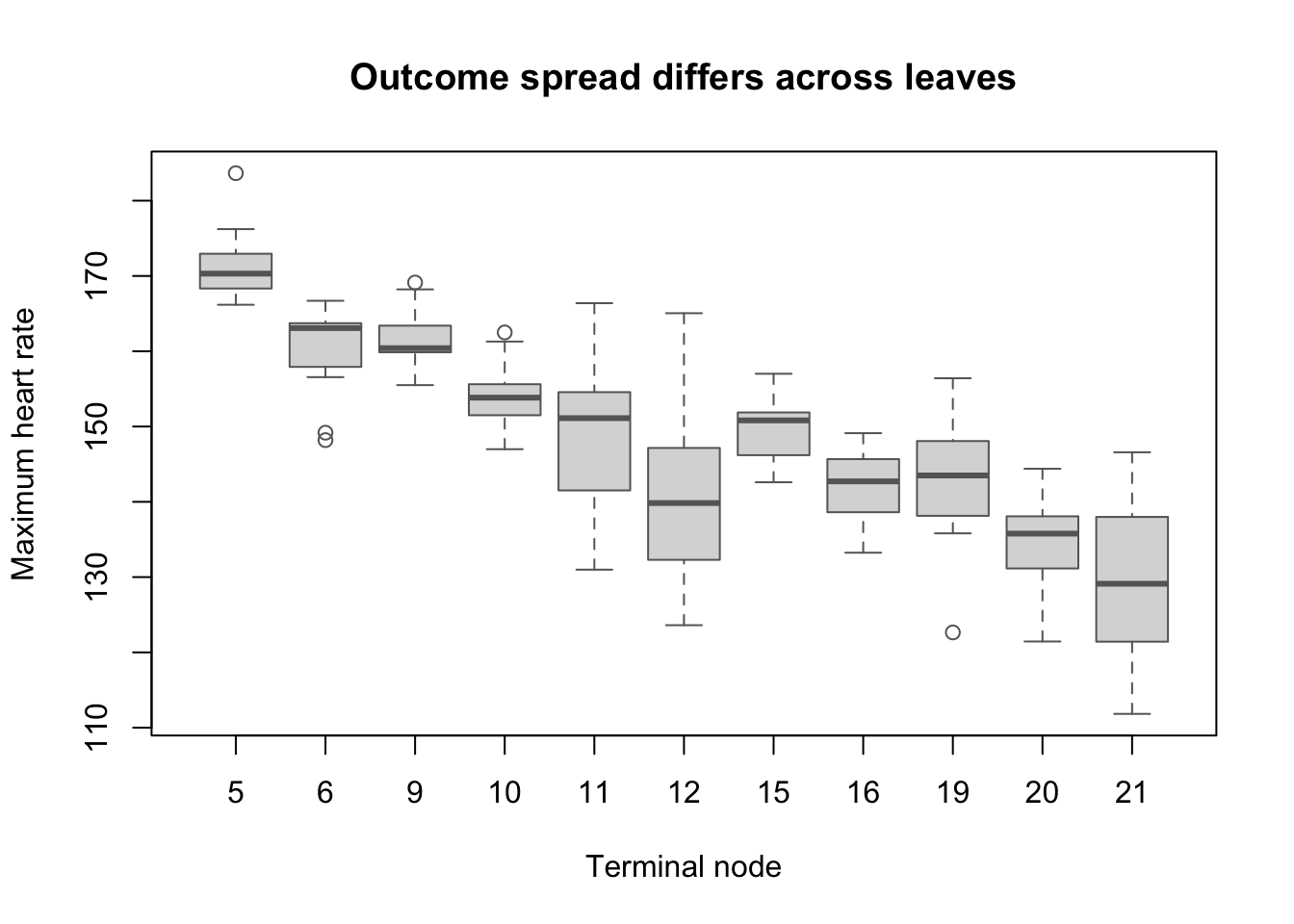
Figure 141.1: Leaf-wise outcome distributions for a regression tree
This is the key idea of leaf diagnostics in one picture: the tree may split the data usefully, but some terminal nodes are still much more variable than others. That difference should appear in how you describe the reliability of predictions.
Detailed interpretation of the synthetic tree example:
The terminal nodes separate high- and low-capacity heart-rate segments; the center of max_rate is materially different across leaves.
The younger low-risk leaves (for example, nodes 5 and 9) have the highest centers and relatively small spread, so their local predictions are comparatively stable.
The medium-risk middle-age leaf (node 11) already shows visibly broader dispersion than the nearby low-risk leaves, even though its center still looks clinically plausible.
The high-risk leaves (especially nodes 12 and 21) have the lowest centers and the widest spread, making them the least stable prediction segments in the figure.
Interpretation rule: do not treat all leaves as equally reliable. The same tree can contain both well-behaved and weakly-behaved prediction bins.
141.7 Interpreting Leaf Reliability
When comparing leaves:
low spread + mild asymmetry -> more stable local predictions,
high spread + heavy tails -> higher uncertainty and lower local reliability,
severe skew/tails -> consider robust summaries or transformation-sensitive interpretation.
This does not invalidate the tree; it improves how predictions are communicated and where model refinement should focus.