The Beta Prime distribution — also called the Inverted Beta or Beta Distribution of the Second Kind — extends the Beta distribution to the positive half-line. While the Beta models a proportion bounded to \([0,1]\), the Beta Prime models a positive ratio with no upper bound, arising naturally in Bayesian hierarchical models and as a distribution for odds ratios.
Formally, the random variate \(X\) defined for the range \(X > 0\), is said to have a Beta Prime Distribution (i.e. \(X \sim \text{BetaPrime}(\alpha, \beta, \theta)\)) with shape parameters \(\alpha > 0\) and \(\beta > 0\), and scale parameter \(\theta > 0\). If \(Y \sim \text{Beta}(\alpha, \beta)\) then \(\theta Y/(1-Y) \sim \text{BetaPrime}(\alpha, \beta, \theta)\).
42.1 Probability Density Function
\[
f(x) = \frac{(x/\theta)^{\alpha-1}(1+x/\theta)^{-\alpha-\beta}}{\theta\,\text{B}(\alpha,\beta)}, \quad x > 0
\]
where \(\text{B}(\alpha, \beta) = \Gamma(\alpha)\Gamma(\beta)/\Gamma(\alpha+\beta)\).
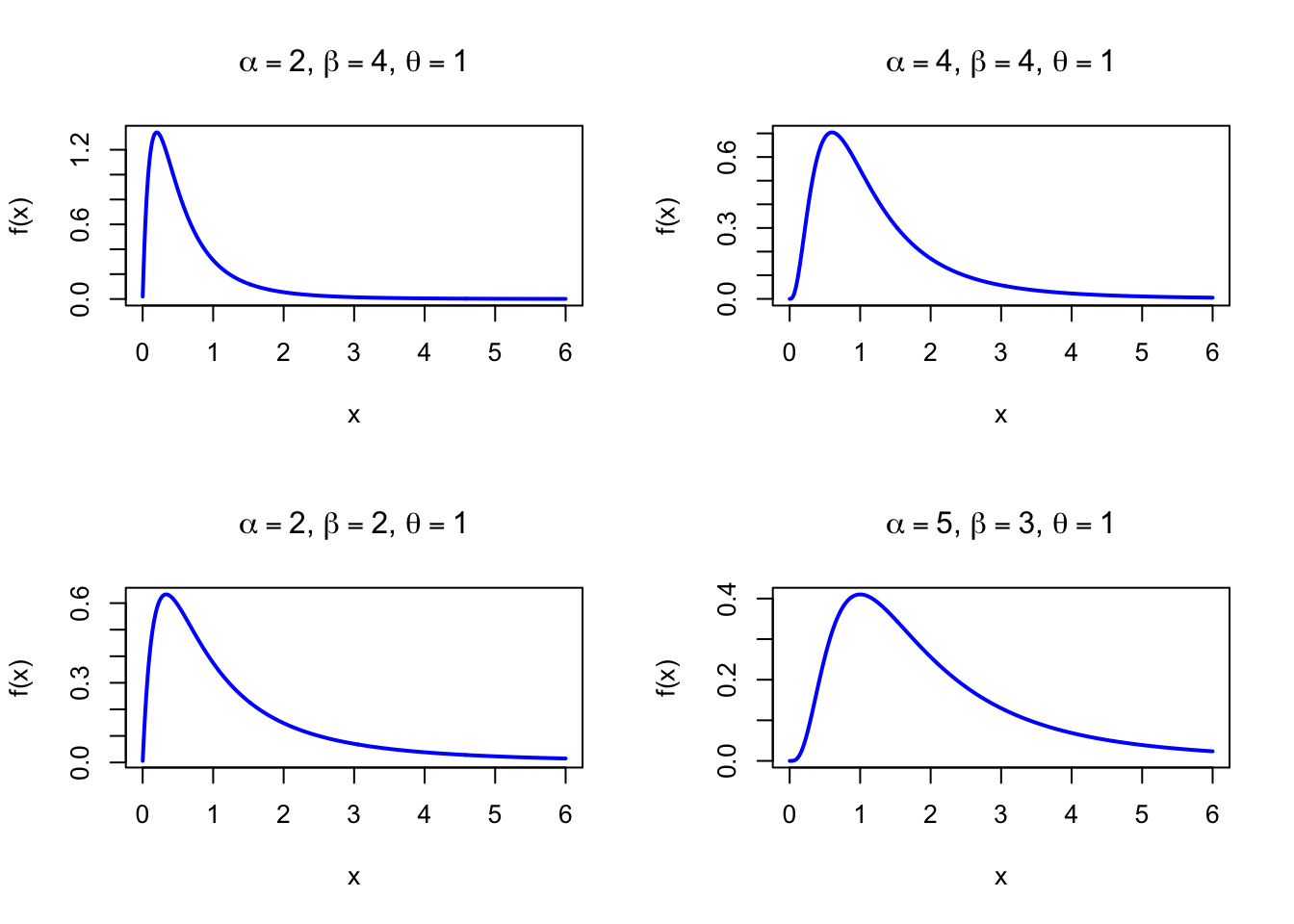
The figure below shows examples of the Beta Prime Probability Density Function for different parameter combinations with \(\theta = 1\).
Code
dbetaprime <-function(x, alpha, beta, theta =1) {ifelse(x >0, (x/theta)^(alpha-1) * (1+ x/theta)^(-alpha-beta) / (theta *beta(alpha, beta)),0)}par(mfrow =c(2, 2))x <-seq(0.001, 6, length =500)plot(x, dbetaprime(x, 2, 4, 1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(paste(alpha==2, ", ", beta==4, ", ", theta==1)))plot(x, dbetaprime(x, 4, 4, 1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(paste(alpha==4, ", ", beta==4, ", ", theta==1)))plot(x, dbetaprime(x, 2, 2, 1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(paste(alpha==2, ", ", beta==2, ", ", theta==1)))plot(x, dbetaprime(x, 5, 3, 1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(paste(alpha==5, ", ", beta==3, ", ", theta==1)))par(mfrow =c(1, 1))
Figure 42.1: Beta Prime Probability Density Function for various parameter combinations (scale = 1)
42.2 Purpose
The Beta Prime distribution models positive, right-skewed quantities for which the support extends to infinity but is bounded below by zero. It generalizes the Beta distribution to the full positive half-line via an odds-ratio transformation and arises naturally in Bayesian inference as a marginal distribution. Common applications include:
Odds ratios in clinical trials and epidemiology (positive, unbounded, right-skewed)
Bayesian hierarchical models: scale parameter priors with heavy right tails
Variance-ratio statistics: the F distribution is a scaled Beta Prime
Financial loss ratios: claim amount relative to policy limit
Reliability and survival: ratio of component strengths or lifetimes
Relation to the discrete setting. The Beta Prime arises in the same way as the Negative Binomial for count data: just as Poisson-Gamma mixture yields the Negative Binomial, a Beta-Prime-type distribution emerges as the marginal of Poisson-Gamma hierarchies for rates. Both generalize their simpler counterparts to handle overdispersion.
42.3 Distribution Function
\[
F(x) = I_{x/(x+\theta)}(\alpha, \beta)
\]
where \(I_u(\alpha, \beta)\) is the regularized incomplete beta function. In R: pbeta(x/(x+theta), shape1 = alpha, shape2 = beta).
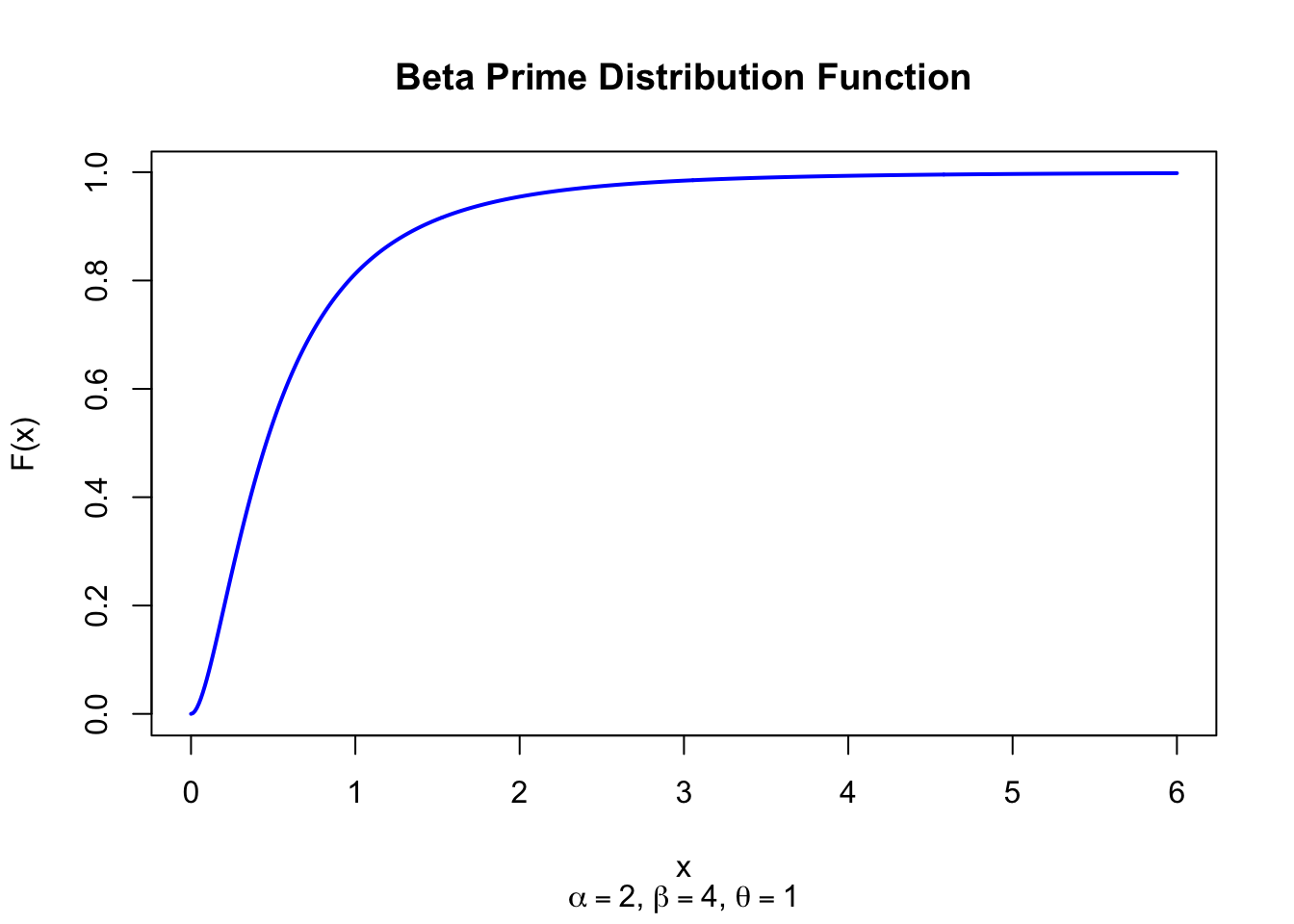
The figure below shows the Beta Prime Distribution Function for \(\alpha = 2\), \(\beta = 4\), \(\theta = 1\).
Code
pbetaprime <-function(x, alpha, beta, theta =1) {ifelse(x >0, pbeta(x / (x + theta), shape1 = alpha, shape2 = beta), 0)}x <-seq(0, 6, length =500)plot(x, pbetaprime(x, 2, 4, 1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="F(x)", main ="Beta Prime Distribution Function",sub =expression(paste(alpha==2, ", ", beta==4, ", ", theta==1)))
Figure 42.2: Beta Prime Distribution Function (alpha = 2, beta = 4, scale = 1)
42.4 Moment Generating Function
The moment generating function does not exist for \(t > 0\) due to the heavy right tail.
An odds ratio for a treatment effect is modeled as \(X \sim \text{BetaPrime}(\alpha = 2, \beta = 4, \theta = 1)\). The mean odds ratio is \(\alpha/(\beta-1) = 2/3\) and the mode is \((\alpha-1)/(\beta+1) = 1/5\).
If \(Y \sim \text{Beta}(\alpha, \beta)\) then \(\theta Y/(1-Y) \sim \text{BetaPrime}(\alpha, \beta, \theta)\). This is the defining property and provides the simplest interpretation: the Beta Prime models odds-ratio-type quantities derived from bounded Beta variates (see Chapter 30).
42.23 Property 2: F Distribution Relationship
If \(X \sim F(2\alpha, 2\beta)\) (Fisher-Snedecor F), then \((\alpha/\beta) X \sim \text{BetaPrime}(\alpha, \beta, 1)\). This means the F distribution is a scaled Beta Prime, and tables of the F distribution implicitly cover the Beta Prime (see Chapter 26).
42.24 Property 3: Lomax (Shifted Pareto) Special Case
When \(\alpha = 1\): \(\text{BetaPrime}(1, \beta, \theta)\) is the Lomax distribution (also known as the shifted Pareto or Pareto Type II). See Chapter 32.
42.25 Related Distributions 1: Beta Distribution
The Beta Prime arises from the Beta via the odds-ratio transformation (see Chapter 30).
42.26 Related Distributions 2: F Distribution
The F distribution is a scaled Beta Prime with integer shape parameters (see Chapter 26).
42.27 Related Distributions 3: Pareto Distribution
The Lomax distribution BetaPrime\((1, \beta, \theta)\) is a shifted Pareto distribution (see Chapter 32).