The Logistic distribution resembles the Normal in shape but has heavier tails. Its CDF — the sigmoid function — is one of the most important functions in statistics and machine learning, forming the mathematical foundation of logistic regression and neural network activations.
Formally, the random variate \(X\) defined for all of \(\mathbb{R}\), is said to have a Logistic Distribution (i.e. \(X \sim \text{Logistic}(\mu, s)\)) with location parameter \(\mu \in \mathbb{R}\) and scale parameter \(s > 0\). In R, the built-in functions are dlogis(x, location = mu, scale = s), plogis, qlogis, and rlogis.
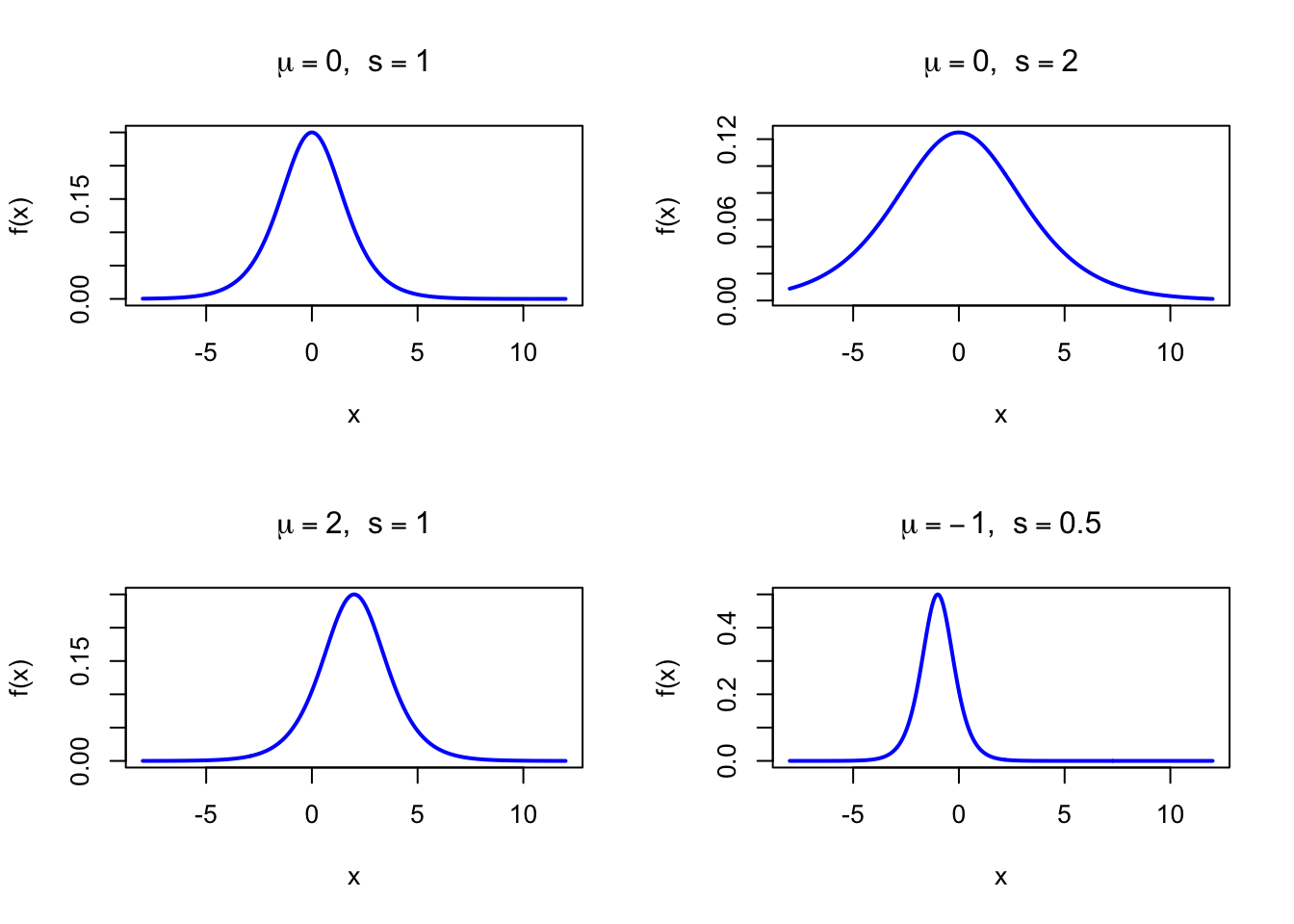
The figure below shows examples of the Logistic Probability Density Function for different parameter combinations.
Code
par(mfrow =c(2, 2))x <-seq(-8, 12, length =500)plot(x, dlogis(x, location =0, scale =1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(paste(mu ==0, ", ", s ==1)))plot(x, dlogis(x, location =0, scale =2), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(paste(mu ==0, ", ", s ==2)))plot(x, dlogis(x, location =2, scale =1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(paste(mu ==2, ", ", s ==1)))plot(x, dlogis(x, location =-1, scale =0.5), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(paste(mu ==-1, ", ", s ==0.5)))par(mfrow =c(1, 1))
Figure 36.1: Logistic Probability Density Function for various parameter combinations
36.2 Purpose
The Logistic distribution is a symmetric, unimodal distribution on \(\mathbb{R}\) that closely resembles the Normal but has heavier tails. Its CDF — the logistic sigmoid function — plays a fundamental role in binary classification models. Common applications include:
Logistic regression: the latent continuous variable whose sign determines the binary outcome
Neural networks: the sigmoid activation function is the Logistic CDF
Growth curve modeling (logistic growth) in biology and ecology
Bioassay and dose-response modeling where response probability increases with dose
Heavy-tailed alternative to the Normal for symmetric continuous data
Relation to the discrete setting. The Logistic distribution is the continuous analog of the Binomial distribution via the logit link: the Binomial models discrete 0/1 outcomes, while the Logistic models their continuous log-odds representation. In logistic regression, binary Binomial outcomes are modeled with a Logistic-distributed latent variable.
36.3 Distribution Function
\[
F(x) = \frac{1}{1+e^{-(x-\mu)/s}}
\]
This is the logistic sigmoid function, one of the most widely used functions in statistics and machine learning.
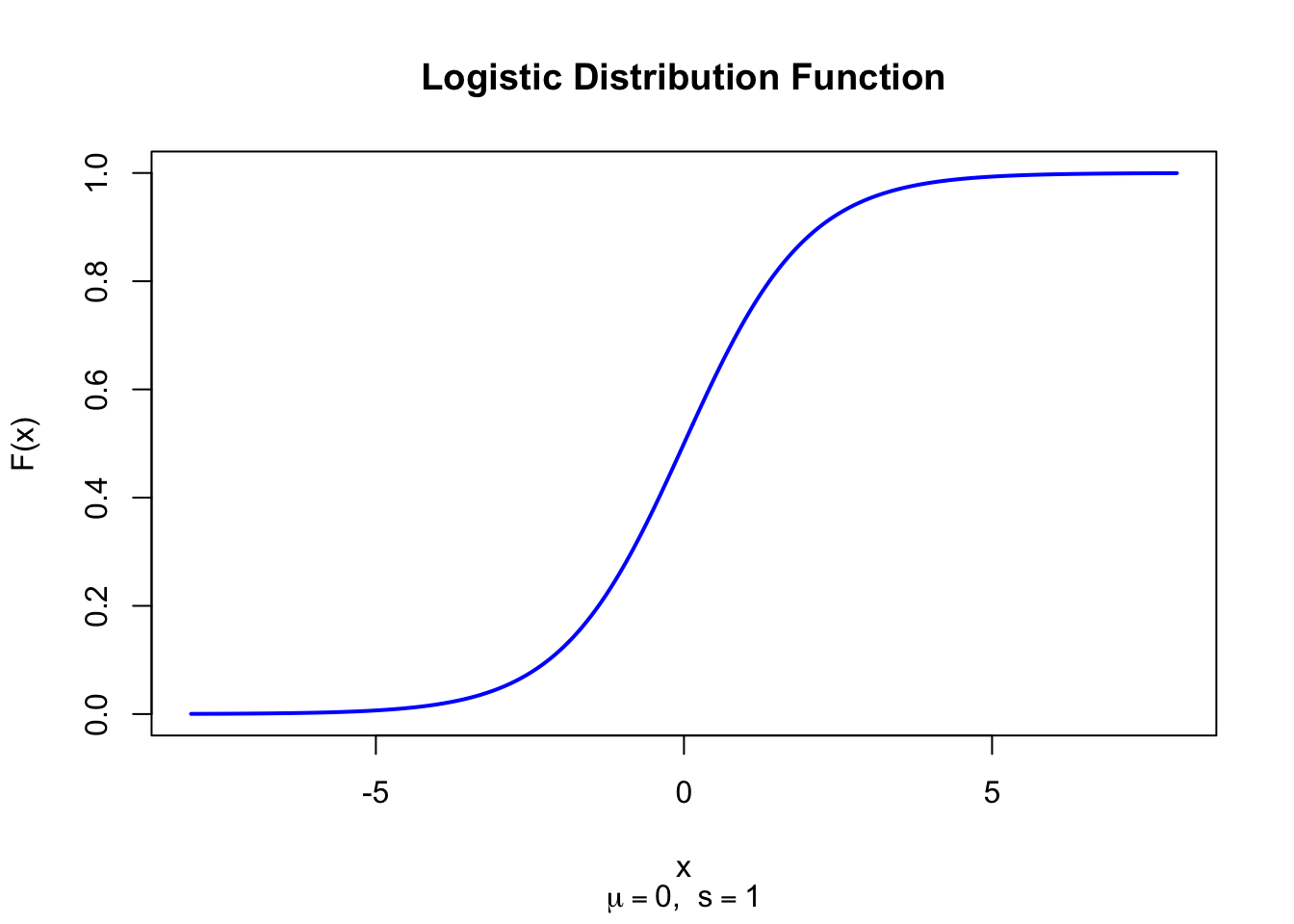
The figure below shows the Logistic Distribution Function for \(\mu = 0\) and \(s = 1\).
Code
x <-seq(-8, 8, length =500)plot(x, plogis(x, location =0, scale =1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="F(x)", main ="Logistic Distribution Function",sub =expression(paste(mu ==0, ", ", s ==1)))
Figure 36.2: Logistic Distribution Function (location = 0, scale = 1)
36.4 Moment Generating Function
\[
M_X(t) = e^{\mu t}\,\frac{\pi s t}{\sin(\pi s t)}, \quad |t| < \frac{1}{s}
\]
The following code demonstrates Logistic probability calculations:
mu <-70; s <-5# Probability density functiondlogis(60, location = mu, scale = s)# Distribution function: P(X <= 60)plogis(60, location = mu, scale = s)# Quantile function (median)qlogis(0.5, location = mu, scale = s)# Generate random Logistic numbersset.seed(42)rlogis(10, location = mu, scale = s)# Standard deviationcat("SD:", s * pi /sqrt(3), "\n")
Logistic random variates are generated via the inverse-CDF method. Since \(F(x) = 1/(1+e^{-(x-\mu)/s})\), the quantile function is the log-odds (logit) function:
\[
X = \mu - s\ln\!\left(\frac{1}{U} - 1\right) \sim \text{Logistic}(\mu, s) \quad \text{when } U \sim \text{U}(0,1)
\]
set.seed(123)n <-1000; mu <-0; s <-1# Inverse-transform methodu <-runif(n)x_inv <- mu - s *log(1/u -1)# Compare with rlogisx_rlogis <-rlogis(n, location = mu, scale = s)cat("Inverse-transform: mean =", round(mean(x_inv), 4)," var =", round(var(x_inv), 4), "\n")cat("rlogis(): mean =", round(mean(x_rlogis), 4)," var =", round(var(x_rlogis), 4), "\n")cat("Theoretical: mean =", mu," var =", round(s^2* pi^2/3, 4), "\n")
Inverse-transform: mean = -0.0202 var = 3.2444
rlogis(): mean = -0.0087 var = 3.2559
Theoretical: mean = 0 var = 3.2899
The CDF \(F(x) = 1/(1+e^{-(x-\mu)/s})\) is the logistic sigmoid function — the foundation of logistic regression. The log-odds (logit) of \(F(x)\) is linear in \(x\):
This elegant identity is unique to the Logistic distribution and is exploited in the derivation of the logistic regression score equations.
36.24 Property 3: Heavier Tails than Normal
The Logistic distribution has kurtosis \(g_2 = 4.2\) versus \(g_2 = 3\) for the Normal. This means the Logistic assigns more probability to values far from the mean — a feature that makes it more robust to outliers in some applications.
36.25 Related Distributions 1: Normal Distribution
The Normal distribution has the same symmetric, bell-shaped form but lighter tails (\(g_2 = 3\)). For most practical purposes, the two distributions are very similar near the center but differ in the tails (see Chapter 20).