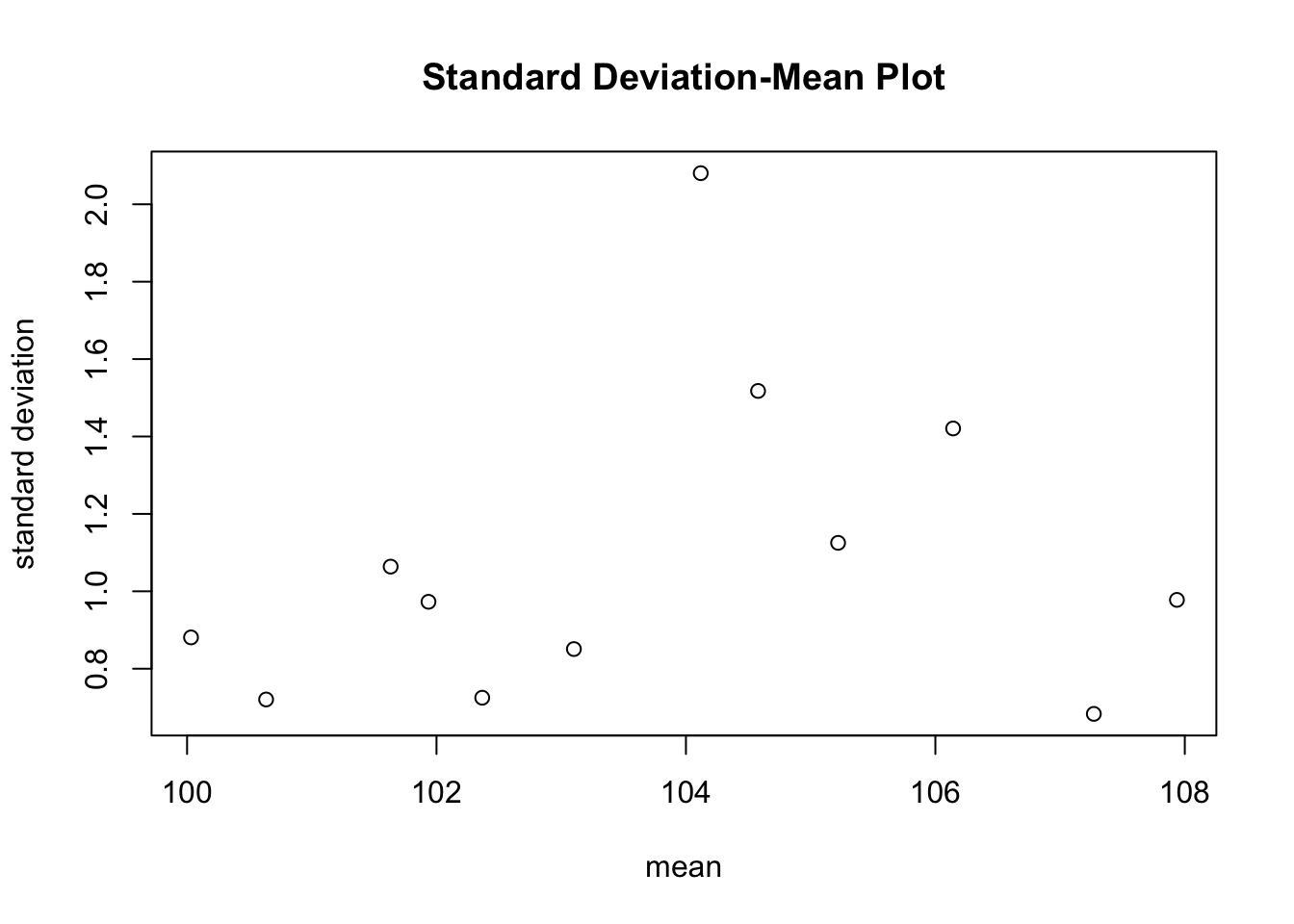
The Standard Deviation-Mean Plot (SMP) consists of a Scatter Plot between the Standard Deviation \(\sigma_i\) versus the Arithmetic Mean \(\mu_i\) for sequential subseries \(i = 1, 2, …, K\). Based on this Scatter Plot, a Simple Linear Regression Model is computed to identify whether or not the Variability (as measured by \(\sigma_i\)) can be explained by (or is associated with) the Central Tendency (as measured by \(\mu_i\)) for each subseries \(i\), i.e.
where \(K\) is the number of sequential subseries and where the width of each subseries is usually chosen such that each index \(i\) represents one year (assuming we are working with time series which have a seasonal sampling frequency, such as monthly or quarterly series).
If the estimated \(\beta\) coefficient, i.e. \(\hat{\beta}\), is either positive or negative, it can be concluded that the Variability of year \(i\) is associated with the level of that same year -- this is an indication that the Variability can be made more stable by transforming the time series through the Box-Cox transformation (Chapter 79).
90.1.1 Horizontal axis
The Horizontal axis of the SMP displays the Arithmetic Mean of subseries \(i\).
90.1.2 Vertical axis
The vertical axis of the SMP displays the Standard Deviation of subseries \(i\).
Min. 1st Qu. Median Mean 3rd Qu. Max.
98.59 101.73 103.32 103.80 105.79 109.71
Call:
lm(formula = arr.sd ~ arr.mean)
Residuals:
Min 1Q Median 3Q Max
-0.52436 -0.25378 -0.06177 0.10253 0.98255
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.52907 5.10576 -0.495 0.631
arr.mean 0.03483 0.04920 0.708 0.495
Residual standard error: 0.4183 on 10 degrees of freedom
Multiple R-squared: 0.04774, Adjusted R-squared: -0.04749
F-statistic: 0.5013 on 1 and 10 DF, p-value: 0.4951
Call:
lm(formula = log(arr.sd) ~ log(arr.mean))
Residuals:
Min 1Q Median 3Q Max
-0.51381 -0.19580 -0.01817 0.13823 0.69431
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -14.717 19.459 -0.756 0.467
log(arr.mean) 3.176 4.192 0.758 0.466
Residual standard error: 0.3429 on 10 degrees of freedom
Multiple R-squared: 0.05429, Adjusted R-squared: -0.04028
F-statistic: 0.574 on 1 and 10 DF, p-value: 0.4661
To compute the Standard Deviation-Mean Plot, the R code uses the standard lm function to compute the linear regression models that are needed for the SMP analysis.
90.3 Purpose
The SMP is used to identify whether or not the Variability of a time series can be explained by its local level (as measured by the Arithmetic Mean). If the linear relationship \(\sigma_i = \alpha + \beta \mu_i + \epsilon_i\) is confirmed then it may be necessary to transform the time series.
90.4 Pros & Cons
90.4.1 Pros
The SMP has the following advantages:
It is easy to compute and provides useful information about the time series.
It allows the user to derive the parameter of the Box-Cox transformation (this will be explained later).
90.4.2 Cons
The SMP has the following disadvantages:
The SMP cannot be computed with many software packages.
Most readers are not familiar with the SMP.
The SMP is sensitive to outliers (just like the Simple Linear Regression Model).
90.5 Example
Let us consider the Airline Data and apply the SMP analysis. The following analysis shows for each section (i.e. year) the Arithmetic Mean (column 2), Standard Deviation (column 3), and Range (column 4).
The corresponding Scatter Plot is also shown. Observe how the dots describe an almost perfect linear relationship between the Standard Deviation \(\sigma_i\) and the Arithmetic Mean \(\mu_i\) of each section \(i\).
The Standard Deviations and Arithmetic Means are used in a Simple Linear Regression Model which allows to estimate the parameters of the regression line that describes the Scatter Plot. The output shows the parameters of the constant term and the slope of the regression line (= 0.1886). This implies that the Standard Deviation (of subsequent years) increases as the Arithmetic Mean increases. Later it will be explained how we can test whether this regression parameter is statistically significant. For now, it is sufficient to know we can (at least) describe the linear relationship between \(\sigma_i\) and \(\mu_i\) based on the SMP.
90.6 Task
Compute the SMP for the monthly Marriages time series and describe your conclusions.