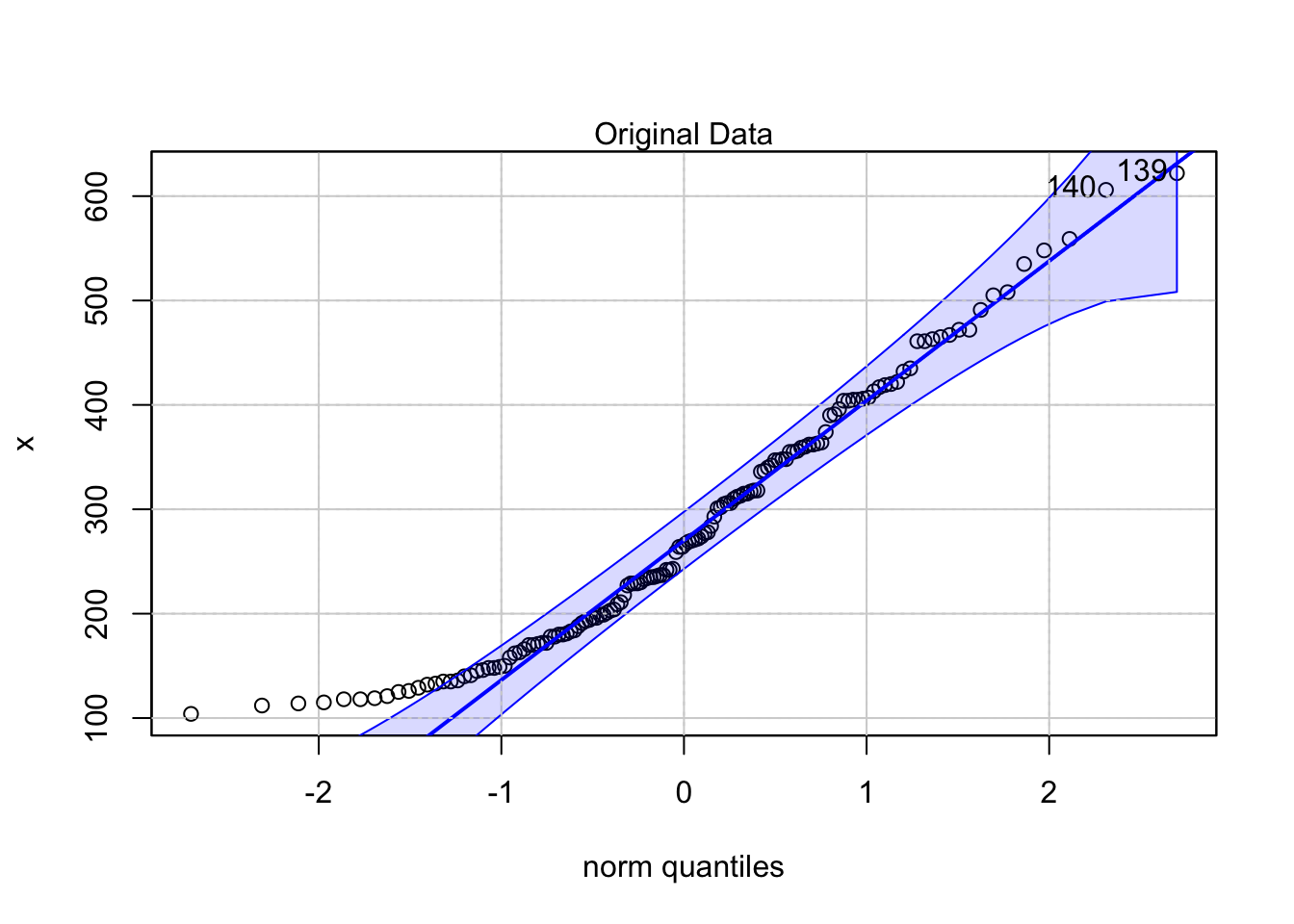
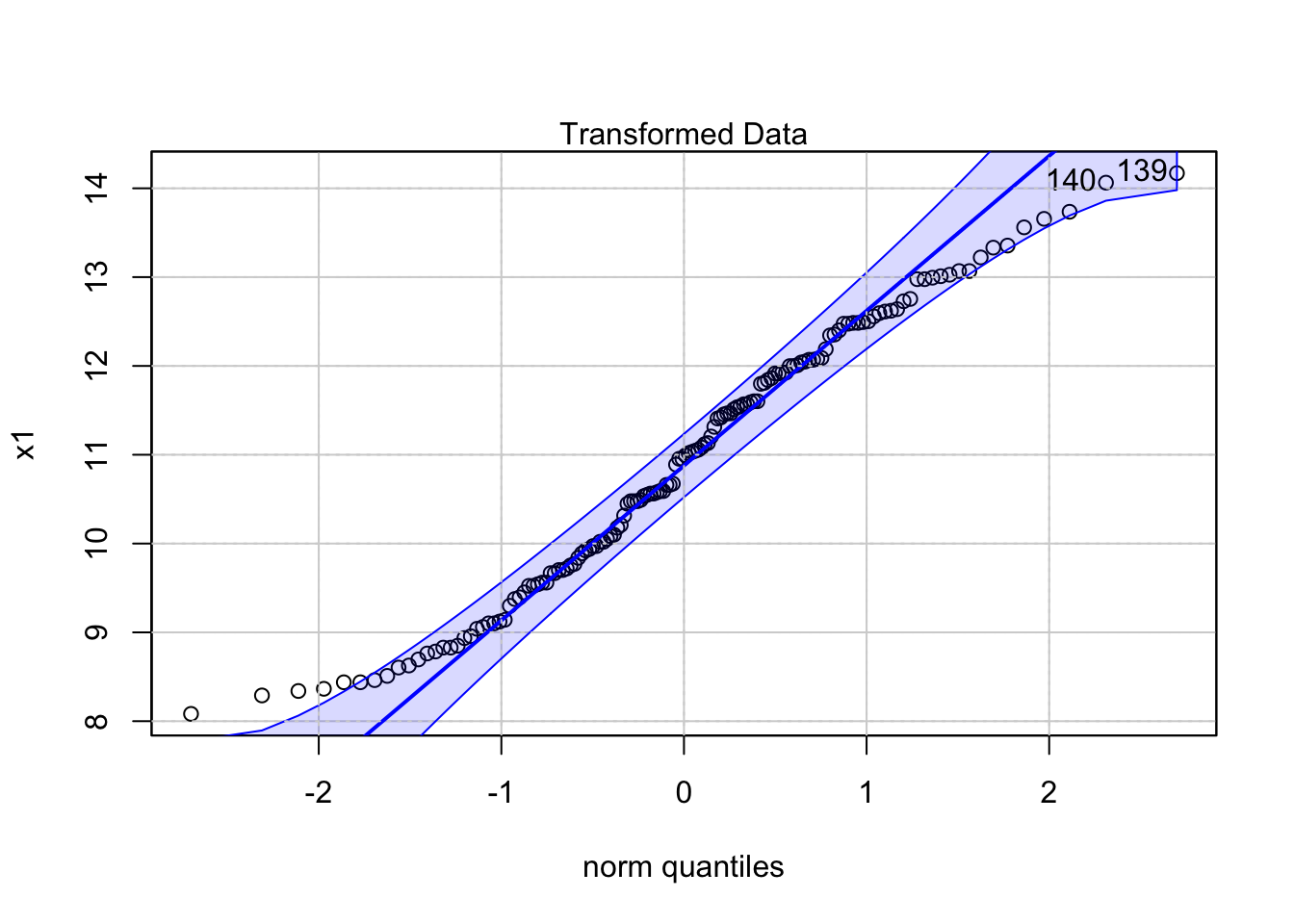
In a first step we need to induce stationarity in the mean and the variance of the time series under investigation. In practice, most time series do not satisfy the stationarity conditions which are required to apply univariate forecasting models. Therefore, these times series are called non-stationary and should be differenced and transformed such that they become stationary with respect to the variance and the mean.
150.1 Stationarity of the mean
With the use of the Autocorrelation Function (ACF) it is possible to detect non-stationarity of the time series with respect to the mean level. As an alternative, it is possible to use the Cumulative Periodogram (CP) to identify non-stationarity. A third diagnostic tool is the so-called Variance Reduction Matrix (VRM) which lists the variances of the time series after several combinations of non-seasonal and seasonal differencing have been applied. As a general rule, the optimal degree of differencing induces stationarity in the mean with a minimum variance.
Stationarity of the mean can be induced by using the backshift and differencing operators. The backshift operator introduces time lags as is illustrated in the following examples:
\(B Y_t = Y_{t-1}\)
\(B^k Y_t = Y_{t-k}\)
\(B_s Y_t = Y_{t-s}\)
\(B^k_s Y_t = Y_{t-k s}\)
The differencing operator is called nabla and transforms the time series in terms of past changes:
In practice, we apply the following differencing operators to induce stationarity in the mean:
\(\nabla^d \nabla^D_s Y_t = W_t\)
where
\(Y_t\) is the original (raw) time series
\(d\) is the degree or order of non-seasonal differencing
\(D\) is the degree or order of seasonal differencing
\(s\) is the seasonal period
\(W_t\) represents the stationary (working) time series
Differencing can be applied to remove non-seasonal and/or seasonal trends. This procedure works reasonably well for a wide range of time series that are naturally observed. Hence, there are only two parameters that need to be determined to induce stationarity in the mean in most commonly encountered time series: the degree of non-seasonal differencing \(d\) and the degree of seasonal differencing \(D\).
As a general rule, we can detect a non-seasonal stochastic trend (unit-root-type behavior) in the ACF if the sequence of the first \(s/2\) autocorrelations exhibits a slowly decreasing pattern. The degree of non-seasonal differencing \(d\) is increased by one unit as long as this pattern is observed. In most cases, the pattern will disappear after a single round of non-seasonal differencing has been applied (i.e. \(d=1\)).
We can detect a seasonal trend in the ACF if the sequence of autocorrelations at lags \({s, 2s, 3s}\) exhibits a slowly decreasing pattern. The degree of seasonal differencing \(D\) is increased by one unit as long as this pattern is observed. In most cases, the pattern will disappear after a single round of seasonal differencing has been applied (i.e. \(D=1\)).
In practice, we will often encounter time series that can be made stationary in the mean through differencing with \(d \in {0, 1, 2}\) and \(D \in {0,1}\).
In addition, we can use the CP to identify seasonal and non-seasonal trend components whenever the CP line exhibits large (step-wise) increases which correspond to the long term or seasonal periods.
150.1.1 Example: Unemployment
The Unemployment time series should be differenced with the non-seasonal differencing operator because the ACF is slowly decreasing, as is shown in the output:
Hence, we set the slider to \(d=1\) (degree of non-seasonal
differencing = 1) and recompute the ACF. The result indicates that the time series also contains a seasonal trend (observe how the ACF at seasonal time lags is slowly decreasing).
Therefore, we must set \(d=D=1\) (\(D\) is the degree of seasonal differencing) by moving the seasonal differencing slider and recompute the ACF.
The ACF (with \(d=D=1\)) suggests that the time series \(\nabla \nabla_{12} Y_t\) is stationary in the mean. This will be verified through spectral analysis in order to gain more confidence in the degrees of non-seasonal and seasonal differencing.
The output shows the CP of the original time series and indicates a non-seasonal stochastic trend because the CP value increases sharply at the frequency of the longest period (i.e. on the left side of the chart).
If we apply non-seasonal differencing (\(d=1\)) then the CP indicates the presence of a seasonal trend. The CP (with \(d=D=1\) and \(s=12\)) suggests that the time series \(\nabla \nabla_{12} Y_t\) is stationary in the mean.
Finally, we examine the VRM (Variance Reduction Matrix) with seasonal period \(s = 12\). The analysis confirms the above findings because the lowest (trimmed) variance can be found for \(d=D=1\):
The ACF and CP seem to suggest \(D=0\) and \(d=0\) (even though there could be doubt about \(d=1\)). The VRM, however, suggests \(D=1\) and \(d=0\). There seems to be a discrepancy between the three diagnostic tools. Therefore, we formulate three alternative models:
Model 1: \(Y_t\)
Model 2: \(\nabla Y_t\)
Model 3: \(\nabla_{12} Y_t\)
150.1.3 Example: Soldiers
We examine the following computations to find the appropriate values for d and D:
All three diagnostics suggest that \(D=0\) and \(d=1\). Therefore we can conclude that \(\nabla Y_t\) is stationary in the mean.
150.1.4 Example: Traffic
The examination of the Traffic data can be obtained in a similar way. Hint: this time series has no seasonality. Therefore, it is not possible to find any seasonal effects.
The ACF and VRM suggest that \(D=0\) and \(d=1\). Based on the CP we may doubt whether \(d=1\) is appropriate or not. Therefore, we formulate two alternative models:
Model 1: \(Y_t\)
Model 2: \(\nabla Y_t\)
150.1.5 Example: Pageviews
The examination of the Pageviews data can be obtained in a similar way. Note: the pageviews time series has a daily sampling frequency. Therefore we should use s=7 instead of s=121.
150.2 Stationarity of the variance
150.2.1 Transformation of time series
If we write a time series \(Y_t\) as the sum of a deterministic mean and a disturbance term
\[
Y_t = \mu_t + e_t
\]
then the relationship between V\((Y_t)\) and \(\mu_t\) may be of the form
\[
\text{V}(Y_t) = \sigma^2 h^2(\mu_t)
\]
where \(h\) is an arbitrary function.
The time series \(Y_t\) must therefore be transformed in order to stabilize the variance. Denote the transformed series by \(g(Y_t)\) and expand it using a Taylor series around \(\mu_t\)
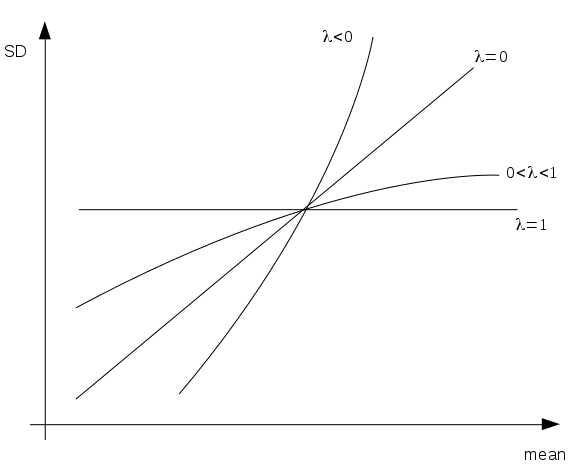
In the Standard Deviation-Mean Plot, the functional relationship is assumed to be as follows
\[
\sigma_{Y_t} = \alpha \mu_{Y_t}^{1-\lambda}
\]
The value of \(\lambda\) is the parameter of the so-called “simple” Box-Cox transformation (Box and Cox 1964)
\[
\begin{cases}Y_t^\lambda \text{ for } \lambda \neq 0 \\\ln Y_t \text{ for } \lambda = 0\end{cases}
\]
Depending on the type of relationship between the Arithmetic Mean and Standard Deviation a different value of \(\lambda\) will be chosen as is shown in Figure 150.1.
Figure 150.1: Theoretical SMP patterns
150.2.2 Standard Deviation-Mean Plot (revisited)
We examine the relationship between the mean and the standard deviation of the time series in order to detect a common form of heteroskedasticity which can be easily removed by the use of a (simplified) Box–Cox transform that is defined as follows: \(Y_t^{\lambda}\) for \(\lambda \neq 0\) and \(\ln Y_t\) for \(\lambda = 0\).
The Standard Deviation-Mean Plot allows us to identify whether a transformation is necessary and it also provides an estimate for \(\lambda\). Note: it is not always possible to find appropriate values for \(\lambda\). In addition, there is no guarantee that the Box-Cox transform allows us to induce stationarity of the Variance. There are many other types of transformation and analysis that might be useful in this respect -- these, however, are beyond the scope of this book.
Formally, the SMP computes two Simple Linear Regression Models based on the Standard Deviation and Arithmetic Mean of sequential blocks. The first model is
for \(i = 1, 2, …, k\), where \(\sigma_i\) is the Standard Deviation, \(\mu_i\) is the Arithmetic Mean, and \(k\) is the number of sequential blocks. In most cases, we use a “block width” which is equal to the seasonal period \(s\) (e.g. \(s=12\) for monthly time series).
The Hypothesis Test which is used to decide whether a Box-Cox transformation is required, is formulated as follows
unless we have prior knowledge about the relationship between \(\sigma_i\) and \(\mu_i\).
If we reject the Null Hypothesis then we decide that a Box-Cox transformation is required, i.e. \(\lambda \neq 1\).
The second Simple Linear Regression Model is only required if the Null Hypothesis H\(_0: \beta = 0\) is rejected. It can be shown that the (quasi-)optimal value for \(\lambda\) can be obtained as follows:
which (implicitly) assumes that \(\forall i = 1, 2, …,k: \mu_i > 0\). If any local mean \(\mu_i \leq 0\) then we simply add a constant \(c\) to all observations such that no negative local means remain.
150.2.3 Box-Cox Normality Plot
150.2.3.1 Definition
As an alternative for the SMP it is sometimes useful to employ the Box-Cox Normality Plot which attempts to estimate the (quasi-)optimal value of \(\lambda\) based on the so-called Maximum Likelihood Estimation procedure.
The Box-Cox Normality Plot features two flavors of the Box-Cox transformation: the so-called “full” version and the “simplified” version.
150.2.3.1.1 Full Box-Cox Transformation
The full Box-Cox transformation is defined as follows
\[
\begin{cases}\frac{sign(Y_t)|Y_t|^\lambda-1}{\lambda} \text{ for } \lambda \neq 0 \\\ln Y_t \text{ for } \lambda = 0\end{cases}
\]
which is the default setting for the Box-Cox Normality Plot.
150.2.3.1.2 Simple Box-Cox Transformation
The simplified Box-Cox transformation has already been defined in the SMP procedure.
150.2.3.2 Horizontal axis
The horizontal axis of the Box-Cox Normality Plot shows the values of \(\lambda\).
150.2.3.3 Vertical axis
The vertical axis of the Box-Cox Normality Plot shows the correlation of the Normal QQ Plot.
150.2.3.4 R Module
The Box-Cox Normality Plot is available on the public website:
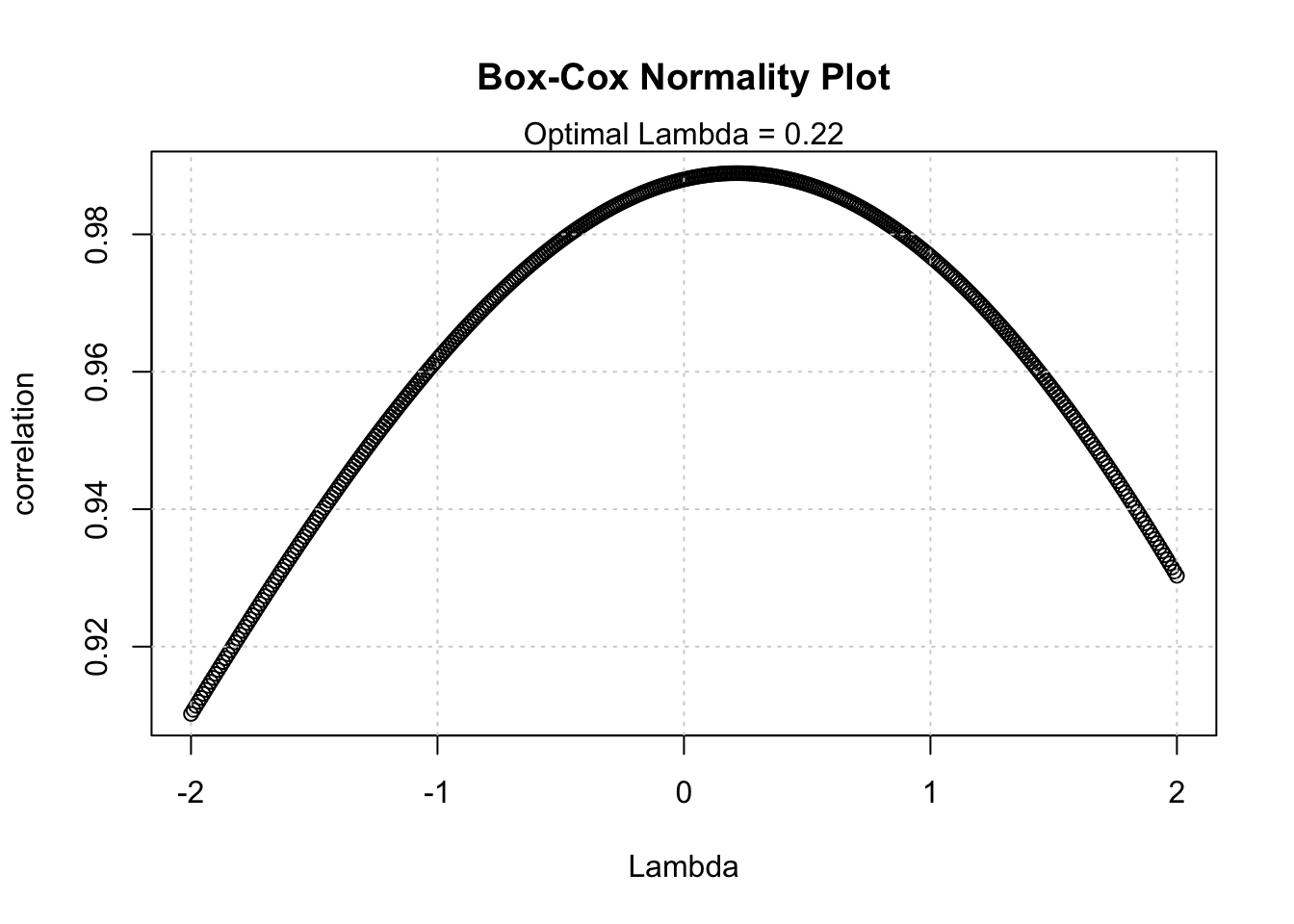
Consider the Airline time series which clearly exhibits a typical form of heteroskedasticity that can be removed through a Box-Cox transformation. The Box-Cox Normality Plot is shown in the following analysis and suggests that \(\lambda \simeq 0.22\) should be appropriate to induce normality2:
The output of the ML estimation shows that \(\lambda\) is (approximately) 0.148 with a 95% confidence interval of [-0.2374, 0.5335] which implies that \(\lambda\) is significantly different from 1 (\(p \simeq 1.59e-05\)) but not significantly different from 0 (\(p \simeq 0.45\)).
From the information shown above it is clear that the Box-Cox transform is able to induce approximate normality in the time series.
150.2.4 Example: Unemployment
Based on the SMP we identify the value for \(\lambda\) of the Box-Cox transformation.
The SMP shows that there is a significant relationship between the standard deviation and the mean of each year. The slope (\(\beta\)) of the regression line is significantly different from zero (\(p \simeq 0.0038\)), i.e. the Null Hypothesis H\(_0: \beta = 0\) is rejected. Hence it is necessary to apply a transformation which induces stationarity of the Variance. The quasi-optimal \(\lambda\) value is computed in the second regression model and is (approximately) equal to 0.47, which could be rounded to 0.5 (this corresponds to \(\sqrt{Y_t}\)). It is possible to apply this rounding because the Standard Deviation of \(\beta\) in the second model is (approximately) 0.115 which implies that \(\beta_0 = 0.5\) is contained in the 2-\(\sigma\) confidence interval around lambda: \(0.5 \in [0.467 - 2 \times 0.115, 0.467 + 2 \times 0.115]\), i.e. \(\lambda\) is not significantly different from 0.5.
We conclude that the Unemployment time series can be transformed in order to induce stationarity of the variance (\(\lambda = 0.5\)).
150.2.5 Example: Births
Based on the SMP we identify the value for \(\lambda\) of the Box-Cox transformation.
The SMP shows that there is no relationship between the standard deviation and the mean of subsequent years. Therefore, there is no need to apply the Box–Cox transformation (\(\lambda = 1\)).
150.2.6 Example: Soldiers
Based on the SMP we identify the value for \(\lambda\) of the Box-Cox transformation.
The SMP shows that there is no relationship between the standard deviation and the mean of sequential years. Therefore, there seems to be no need to apply the Box–Cox transformation (\(\lambda = 1\)).
Unfortunately, the SMP analysis for this time series might be somewhat misleading because the relationship between \(\sigma_i\) and \(\mu_i\) (for \(i = 1, 2, …,k\)) is probably not a linear one. The analysis clearly shows that the last year of the time series is drastically different from the previous years. Both \(\sigma_k\) and \(\mu_k\) are very small compared to the other years (the decision to withdraw troops from Iraq clearly resulted in fewer casualties). This can also be observed in the scatter plots of the analysis: the last year is shown in the bottom left area of the graph. If we would eliminate the last year from the computation, we would probably see a completely different regression line (one with a slightly negative slope).
We conclude that the SMP analysis is not always suited as a tool to find (quasi-)optimal values for \(\lambda\). The Simple Linear Regression Model can be (very) sensitive to outliers which may lead to wrong conclusions. We should always keep in mind that statistical methods make assumptions (which are not always satisfied).
150.2.7 Example: Traffic
Based on the SMP (with seasonality set to 7), we identify the value for \(\lambda\) of the Box-Cox transformation.
The SMP shows that there is a relationship between the standard deviation and the mean of sequential years. The slope (\(\beta\)) of the regression line is significantly different from zero (\(p \simeq 2e-16\)). The quasi-optimal \(\lambda\) value in the second regression equals -0.28 which cannot be rounded to 0 because the standard deviation is 0.08. In other words, the Traffic time series can be transformed in order to induce stationarity of the variance.
150.2.8 Example: Pageviews
To compute the SMP for the Pageviews time series we have to use a seasonality parameter of 7 instead of 12.
The SMP indicates a strong relationship between the standard deviation and the mean of sequential years. The slope (\(\beta\)) of the regression line is significantly different from zero (\(p < 2e-16\)). The quasi-optimal \(\lambda\) value can also be computed in a second regression (0.11) which must not be rounded to 0 because the standard deviation is only 0.036. In other words, the Pageviews time series should be transformed with \(\lambda = 0.11\) (i.e. \(Y_t^{0.11}\)) in order to induce stationarity.
150.3 Why do we need stationarity?
The most fundamental justification for time series analysis (as described in this chapter) is due to Wold’s decomposition theorem (Wold 1938). In practical terms, it states that a stationary time series can be decomposed into two parts: (1) a predictable component that is fully determined by past information, and (2) an innovation component driven by current and past shocks. The innovation component is generally represented as a one-sided moving-average expansion (not necessarily a finite-order MA model).
What does this all mean? In simple words, once stationarity has been induced, AR/MA/ARMA models provide useful finite approximations to the underlying dynamics. There is no general theorem guaranteeing that every arbitrary time series can be transformed into a stationary one. In applied work, however - especially for many economic time series - approximate stationarity can often be induced through transformations and differencing, but this should always be verified with diagnostics.
Box, George E. P., and David R. Cox. 1964. “An Analysis of Transformations.”Journal of the Royal Statistical Society. Series B (Methodological) 26 (2): 211–52. https://doi.org/10.1111/j.2517-6161.1964.tb00553.x.
Wold, Herman. 1938. A Study in the Analysis of Stationary Time Series. Uppsala: Almqvist & Wiksell.
Actually, the time series could have multiple levels of seasonality (weekly, monthly, and annually). In this case, however, we limit ourselves to the investigation of weekly seasonality only.↩︎
It is often the case that transforming data towards normality also helps to induce stationarity of the variance. Strictly speaking, however, normality and stationarity (of the variance) are not the same.↩︎