Any stationary time series can be modelled by AR and MA models as is shown in Wold’s decomposition theorem (Wold 1938). The definitions and properties of (some of) these models are described in the following sections.
where \(W_t\) is a stationary time series, \(e_t\) is a white noise error term, and \(F_t\) is called the forecast or prediction. Now we derive the theoretical pattern of the ACF of an AR(1) process for identification purposes.
First, we note that the above expression may be rewritten as follows
such that \(\rho_k = \phi_1 \rho_{k-1} = \phi_1^2 \rho_{k-2} = \phi_1^3 \rho_{k-3} = \cdots\). We conclude that \(\rho_k = \phi_1^k \rho_0 = \phi_1^k\).
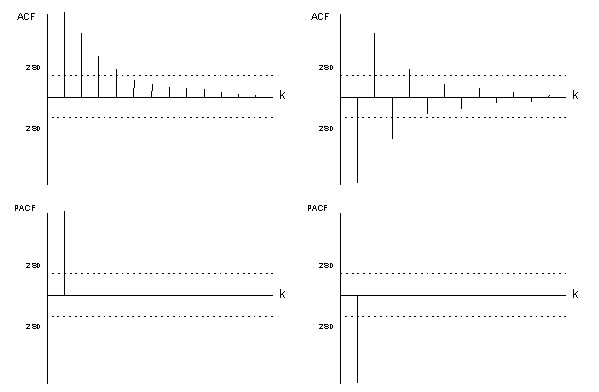
Figure 151.1: Theoretical ACF/PACF of AR(1) process
Figure 151.1 shows two theoretical patterns that occur in the ACF and PACF when the stationary time series \(W_t\) follows an AR(1) process. Note that the first ACF and PACF coefficients are always equal.
Generally speaking, a linear filter process is stationary if the inverse-filter expansion converges. For AR(1), stationarity requires \(|\phi_1|<1\). Equivalently, the root of \((1-\phi_1 B)=0\) is \(B=1/\phi_1\), which must lie outside the unit circle (absolute value greater than 1).
\[
\forall i \in \{1,2,\ldots,p\}: \left|\xi_i\right| < 1
\]
must be satisfied in order to obtain stationarity.
Equivalent statement (often used in textbooks): if roots are written in the polynomial variable \(z\) for \(\\phi(z)=0\), those roots must lie outside the unit circle. Both formulations describe the same stationarity condition.
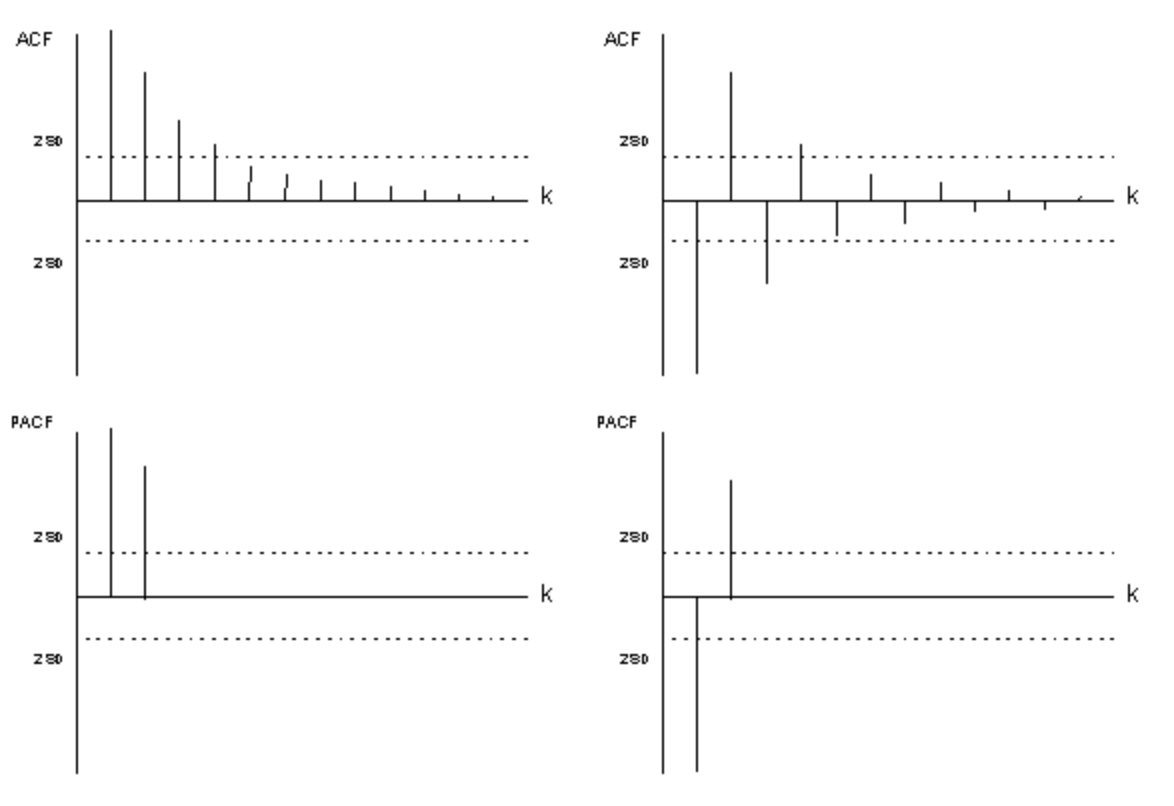
The model is stationary if the \(\psi_i\) weights converge. This is the case when some conditions on \(\phi_1\) and \(\phi_2\) are imposed. These conditions can be found on using the solutions of the polynomial of the AR(2) model. The so-called characteristic equation is used to find these solutions
\[
(1 - \phi_1 B - \phi_2 B^2) = (1 - \xi_1 B)(1 - \xi_2 B) = 0
\]
which can be either real or complex. Note that the roots are complex if \(\phi_1^2 + 4 \phi_2 < 0\). When these solutions (in absolute values) are smaller than 1, the AR(2) model is stationary.
It can be shown that these conditions are satisfied if \(\phi_1\) and \(\phi_2\) lie inside of the Stralkowski triangular region which is restricted by
R’s arima() function uses the MA sign convention \((1 + \\theta_1 B)\), which is the opposite sign of the convention used in this chapter. Therefore, ma = c(-0.8) in R corresponds to \(\\theta_1 = 0.8\) here.
where \(W_t\) is a stationary time series and \(e_t\) is a white noise error term. The current observation depends on the current and previous error term. We now derive the theoretical ACF of the MA(1) process.
We compute the autocovariance at lag \(k\) by multiplying \(W_t\) by \(W_{t-k}\) in expectations form
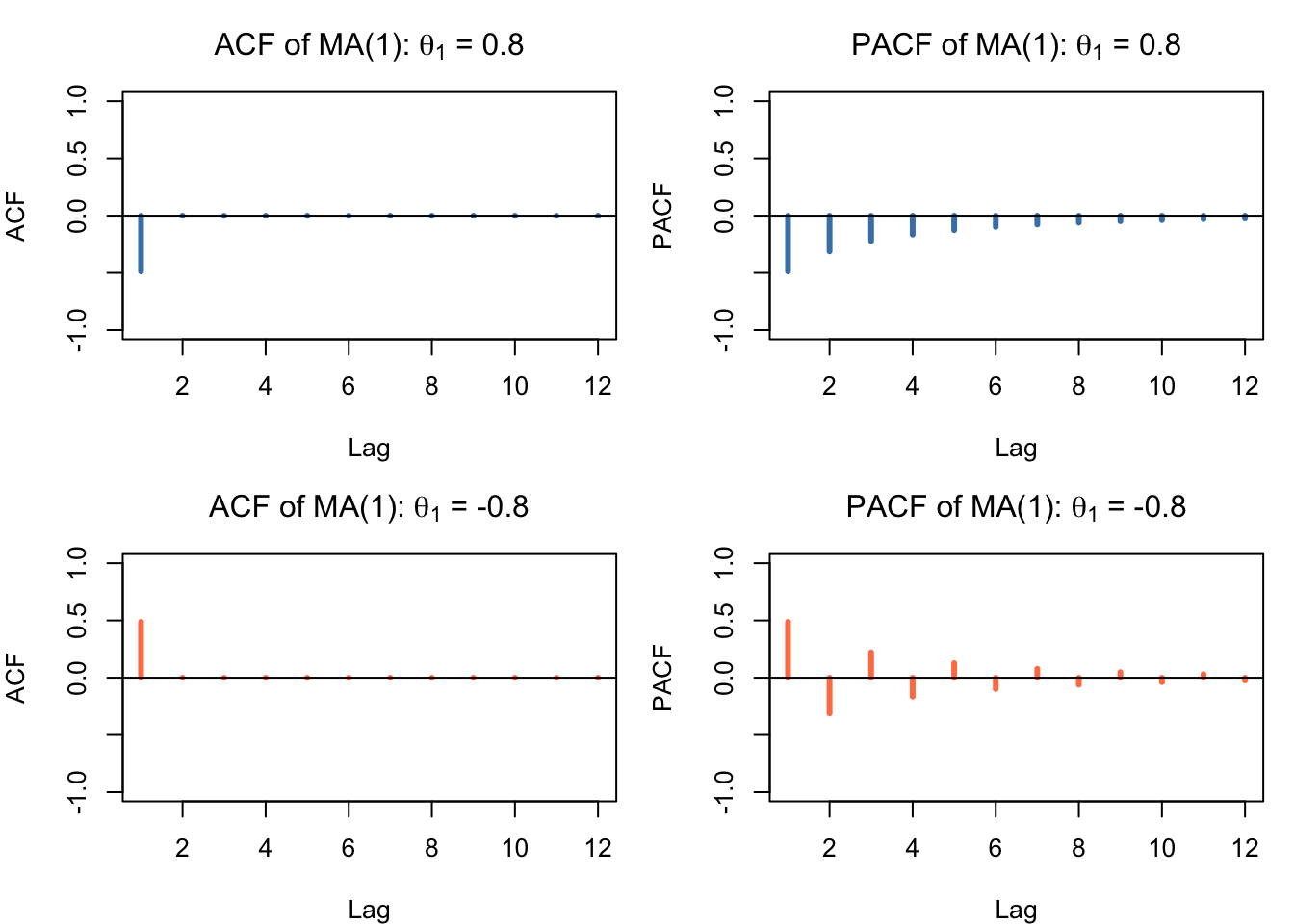
The ACF of an MA(1) process cuts off after lag 1, while the PACF shows an exponential decay (tailing off). This pattern is the mirror image of the AR(1) process where the ACF decays and the PACF cuts off.
The MA(1) model is invertible if the root of \((1 - \theta_1 B) = 0\) is larger than 1 in absolute value, which requires \(|\theta_1| < 1\). Invertibility ensures that the MA representation can be rewritten as an infinite AR process and guarantees uniqueness of the model.
par(mfrow =c(2, 2), mar =c(4, 4, 3, 1))# MA(1) with positive thetaacf_vals <-ARMAacf(ma =c(-0.8), lag.max =12)pacf_vals <-ARMAacf(ma =c(-0.8), lag.max =12, pacf =TRUE)plot(1:12, acf_vals[-1], type ="h", lwd =3, col ="steelblue",xlab ="Lag", ylab ="ACF", main =expression(paste("ACF of MA(1): ", theta[1], " = 0.8")),ylim =c(-1, 1))abline(h =0)plot(1:12, pacf_vals, type ="h", lwd =3, col ="steelblue",xlab ="Lag", ylab ="PACF", main =expression(paste("PACF of MA(1): ", theta[1], " = 0.8")),ylim =c(-1, 1))abline(h =0)# MA(1) with negative thetaacf_vals2 <-ARMAacf(ma =c(0.8), lag.max =12)pacf_vals2 <-ARMAacf(ma =c(0.8), lag.max =12, pacf =TRUE)plot(1:12, acf_vals2[-1], type ="h", lwd =3, col ="coral",xlab ="Lag", ylab ="ACF", main =expression(paste("ACF of MA(1): ", theta[1], " = -0.8")),ylim =c(-1, 1))abline(h =0)plot(1:12, pacf_vals2, type ="h", lwd =3, col ="coral",xlab ="Lag", ylab ="PACF", main =expression(paste("PACF of MA(1): ", theta[1], " = -0.8")),ylim =c(-1, 1))abline(h =0)par(mfrow =c(1, 1))
Figure 151.4: Theoretical ACF/PACF of MA(1) process
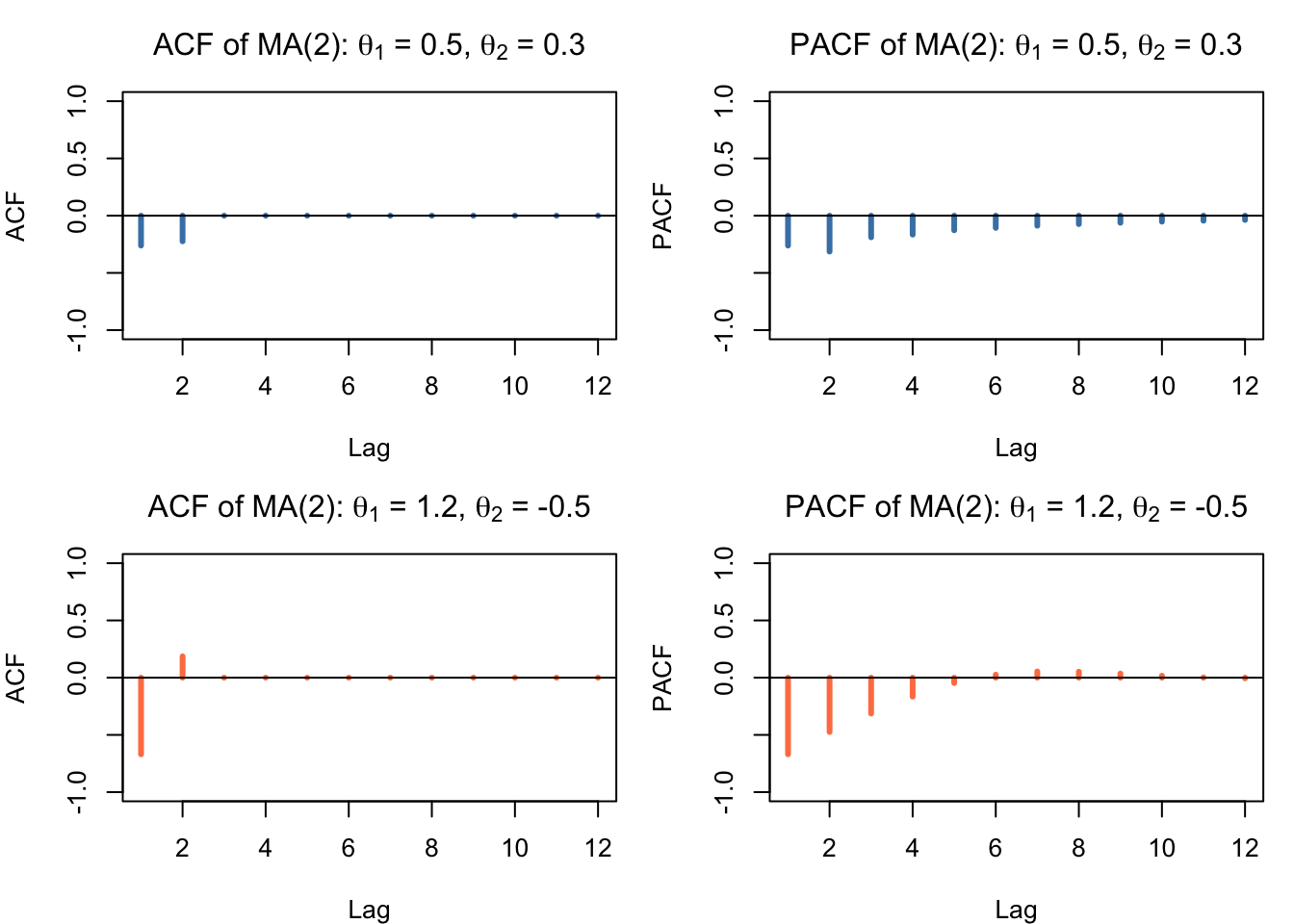
The ACF of an MA(2) process therefore cuts off after lag 2, while the PACF shows a decay pattern. The invertibility conditions require that the roots of the characteristic equation \((1 - \theta_1 B - \theta_2 B^2) = 0\) lie outside the unit circle, analogously to the stationarity conditions for the AR(2) model.
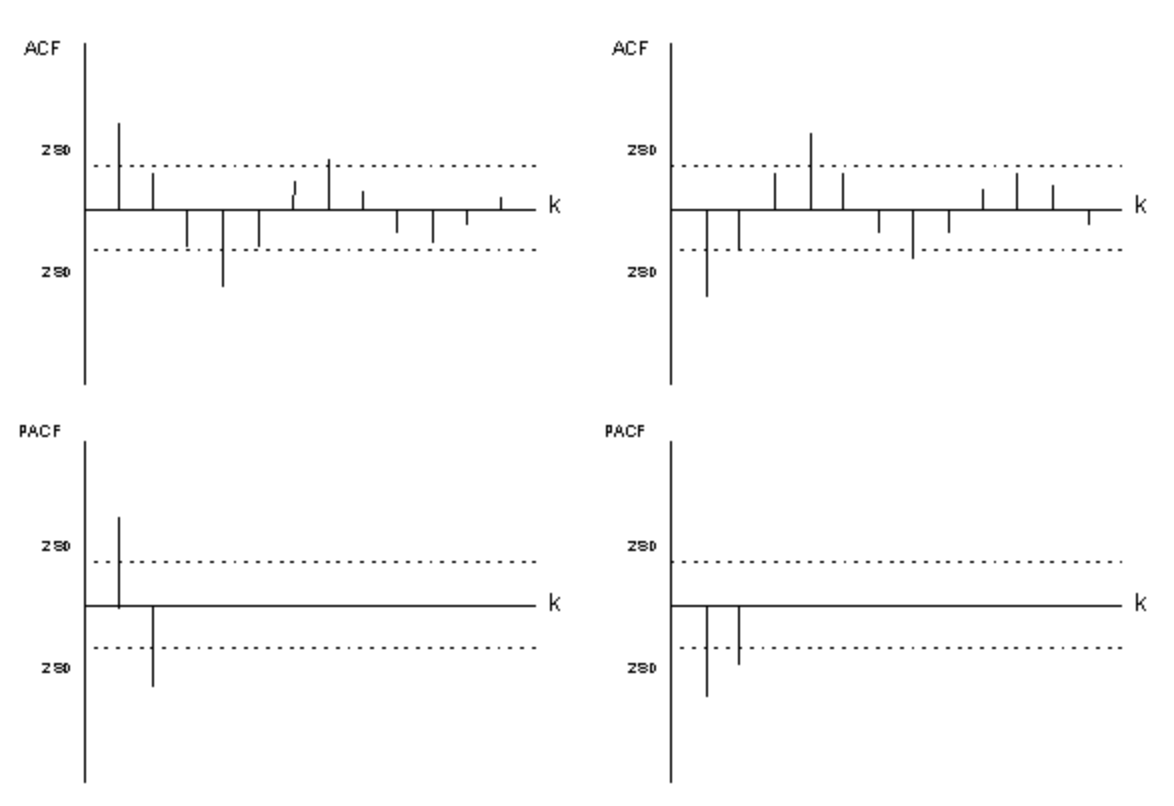
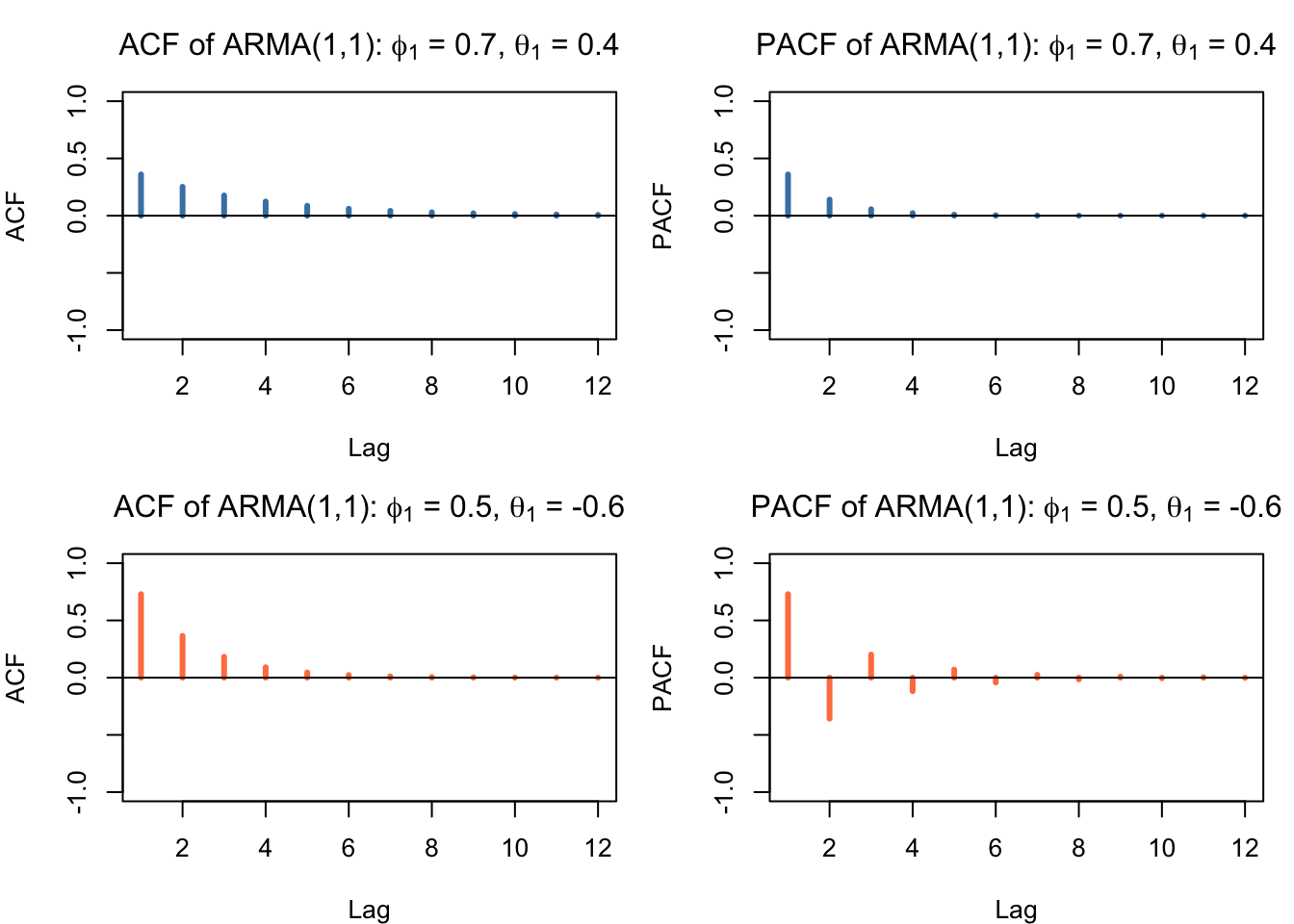
followed by exponential decay: \(\rho_k = \phi_1 \rho_{k-1}\) for \(k > 1\). The PACF also shows a decay pattern. Since both the ACF and PACF decay (neither cuts off cleanly), it is difficult in practice to identify an ARMA model from the ACF/PACF alone. This is precisely why the backward selection approach (Chapter 152) is so useful: rather than trying to identify exact values of \(p\) and \(q\) from theoretical patterns, we start with maximum values and let the estimation procedure eliminate non-significant parameters.
par(mfrow =c(2, 2), mar =c(4, 4, 3, 1))acf_vals <-ARMAacf(ar =c(0.7), ma =c(-0.4), lag.max =12)pacf_vals <-ARMAacf(ar =c(0.7), ma =c(-0.4), lag.max =12, pacf =TRUE)plot(1:12, acf_vals[-1], type ="h", lwd =3, col ="steelblue",xlab ="Lag", ylab ="ACF",main =expression(paste("ACF of ARMA(1,1): ", phi[1], " = 0.7, ", theta[1], " = 0.4")),ylim =c(-1, 1))abline(h =0)plot(1:12, pacf_vals, type ="h", lwd =3, col ="steelblue",xlab ="Lag", ylab ="PACF",main =expression(paste("PACF of ARMA(1,1): ", phi[1], " = 0.7, ", theta[1], " = 0.4")),ylim =c(-1, 1))abline(h =0)acf_vals2 <-ARMAacf(ar =c(0.5), ma =c(0.6), lag.max =12)pacf_vals2 <-ARMAacf(ar =c(0.5), ma =c(0.6), lag.max =12, pacf =TRUE)plot(1:12, acf_vals2[-1], type ="h", lwd =3, col ="coral",xlab ="Lag", ylab ="ACF",main =expression(paste("ACF of ARMA(1,1): ", phi[1], " = 0.5, ", theta[1], " = -0.6")),ylim =c(-1, 1))abline(h =0)plot(1:12, pacf_vals2, type ="h", lwd =3, col ="coral",xlab ="Lag", ylab ="PACF",main =expression(paste("PACF of ARMA(1,1): ", phi[1], " = 0.5, ", theta[1], " = -0.6")),ylim =c(-1, 1))abline(h =0)par(mfrow =c(1, 1))
Figure 151.6: Theoretical ACF/PACF of ARMA(1,1) process
151.6 ARMA Identification Summary
The table below summarises the theoretical ACF and PACF patterns for the most common models. These patterns form the basis of the Box-Jenkins identification step.
Table 151.1: ACF/PACF identification patterns
Model
ACF pattern
PACF pattern
AR(1)
Exponential decay
Cuts off after lag 1
AR(2)
Exponential or sinusoidal decay
Cuts off after lag 2
AR(p)
Decays (exponential and/or sinusoidal)
Cuts off after lag p
MA(1)
Cuts off after lag 1
Exponential decay
MA(2)
Cuts off after lag 2
Exponential or sinusoidal decay
MA(q)
Cuts off after lag q
Decays (exponential and/or sinusoidal)
ARMA(p,q)
Tails off (no clean cutoff)
Tails off (no clean cutoff)
In practice, the sample ACF and PACF are noisy estimates of the theoretical patterns, making it hard to distinguish between “cutting off” and “decaying” especially for mixed ARMA models. This is why the ARIMA Backward Selection approach described in the next chapters is recommended as the primary identification strategy.
151.7 Practical Identification Workflow
In real datasets, a practical workflow is usually more reliable than pattern matching alone:
Transform and difference first (\(\\lambda\), \(d\), \(D\)) so the working series is approximately stationary.
Inspect ACF/PACF of the stationary series and propose small candidate sets for \((p,q,P,Q)\).
Fit a deliberately general candidate (e.g., modest maxima for \(p,q,P,Q\)) and simplify.
Compare candidates using information criteria (AIC/BIC; Akaike (1974); Schwarz (1978)) and residual diagnostics (ACF/PACF, Ljung-Box (Ljung and Box 1978), normality checks).
Keep the most parsimonious model that passes diagnostics and still forecasts well out of sample.
This chapter focuses on Step 2 (theoretical identification patterns). The implementation of Steps 3–5 is provided in Chapter 152.
151.8 Identifying ARMA Parameters in Practice
The complete ARIMA(p,d,q)(P,D,Q)-lambda model is defined by the following equation:
Before we can estimate the AR and MA parameters we need to identify the appropriate values for \(\lambda\), d, D, p, q, P, and Q. We already know how to determine \(\lambda\), d, and D. The other parameters may be identified through careful examination of the ACF and Partial ACF (PACF) about the stationary time series (for instance, the theoretical ACF and PACF patterns that correspond to the AR(1) process).
It requires a lot of experience to identify the values for p, q, P, and Q based on the theoretical patterns of AR and MA models. Therefore we introduce an easier method (ARIMA Backward selection) which is based on a trial-and-error strategy that simplifies a general model (see next section).
Akaike, Hirotugu. 1974. “A New Look at the Statistical Model Identification.”IEEE Transactions on Automatic Control 19 (6): 716–23. https://doi.org/10.1109/TAC.1974.1100705.
Ljung, Greta M., and George E. P. Box. 1978. “On a Measure of Lack of Fit in Time Series Models.”Biometrika 65 (2): 297–303. https://doi.org/10.1093/biomet/65.2.297.