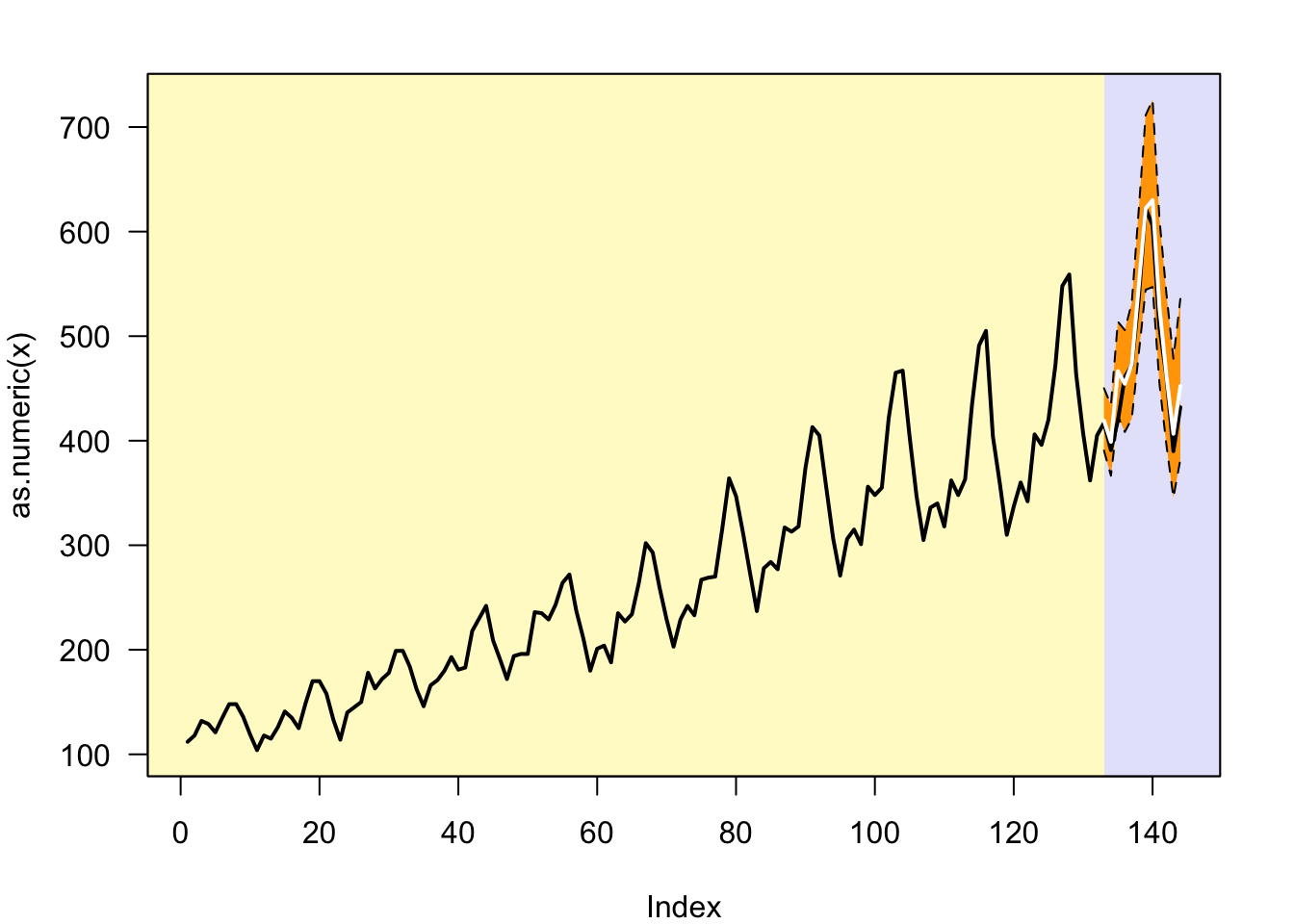
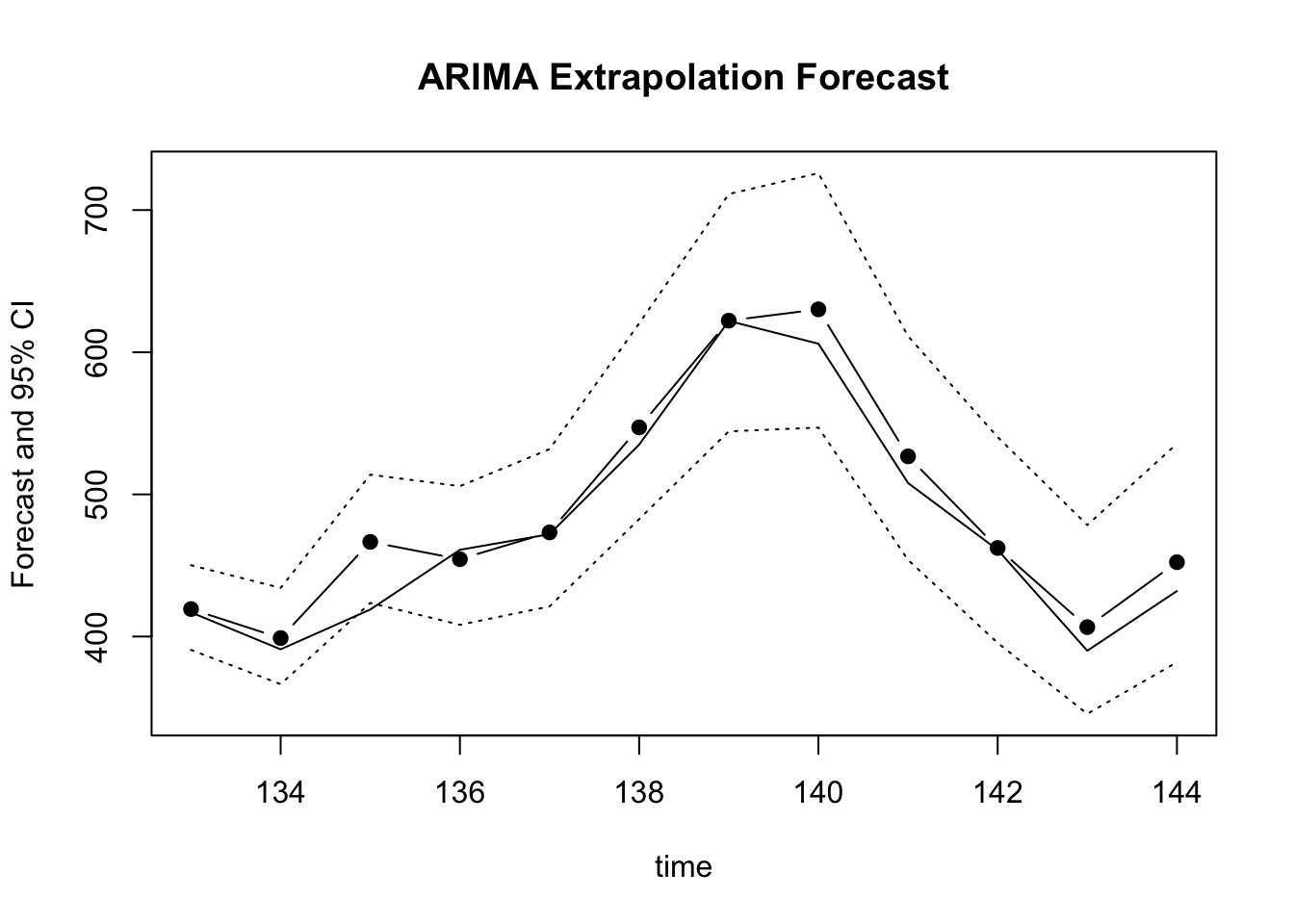
The computation shown above (click on the Forecast tab first!) allows us to conclude that:
the expected forecast uncertainty is small on the short run (4%) and relatively high on the long run (28%)
the actual forecast error is much smaller than the expected error
the ceteris paribus conditions are satisfied during the last 12 months (there were no exceptional events)
The extrapolation forecast clearly captures the seasonal pattern and the local trend, as can be observed in the figure near the bottom of the output. The figure also shows that the forecast track is closely aligned with the actual values from the cut-off period. In addition, the actual values are included in the 95% prediction intervals, indicating that the observed forecast errors are compatible with the model’s expected uncertainty for \(t = 361, 362, …, 372\).
153.1.1 Generic Local Template (AirPassengers placeholder)
If you prefer to compute ARIMA forecasting on your local machine, the following script is intentionally generic. It uses AirPassengers as a placeholder dataset.
To replicate this chapter’s Unemployment example, replace x <- AirPassengers with the Unemployment series and keep the same ARIMA settings.
library(lattice)x <- AirPassengers # placeholder dataset for the generic templatepar1 =12#cut off periodspar2 =0.0#Box-Cox lambda transformation parameterpar3 =1#degree of non-seasonal differencingpar4 =1#degree of seasonal differencingpar5 =12#seasonal periodpar6 =0#degree (p) of the non-seasonal AR(p) polynomialpar7 =1#degree (q) of the non-seasonal MA(q) polynomialpar8 =0#degree (P) of the seasonal AR(P) polynomialpar9 =1#degree (Q) of the seasonal MA(Q) polynomialpar10 =FALSE#Include mean?if (par2 ==0) x <-log(x)if (par2 !=0) x <- x^par2lx <-length(x)first <- lx -2*par1nx <- lx - par1nx1 <- nx +1fx <- lx - nxif (fx <1) { fx <- par5*2 nx1 <- lx + fx -1 first <- lx -2*fx}first <-1if (fx <3) fx <-round(lx/10,0)arima.out <-arima(x[1:nx], order=c(par6,par3,par7), seasonal=list(order=c(par8,par4,par9), period=par5), include.mean=par10, method='ML')forecast <-predict(arima.out,fx)lb <- forecast$pred -1.96* forecast$seub <- forecast$pred +1.96* forecast$seif (par2 ==0) { x <-exp(x) forecast$pred <-exp(forecast$pred) lb <-exp(lb) ub <-exp(ub)}if (par2 !=0) { x <- x^(1/par2) forecast$pred <- forecast$pred^(1/par2) lb <- lb^(1/par2) ub <- ub^(1/par2)}if (par2 <0) { olb <- lb lb <- ub ub <- olb}actandfor <-c(x[1:nx], forecast$pred)perc.se <- (ub-forecast$pred)/1.96/forecast$predopar <-par(mar=c(4,4,2,2),las=1)ylim <-c( min(x[first:nx],lb), max(x[first:nx],ub))plot(as.numeric(x),ylim=ylim,type='n',xlim=c(first,lx))usr <-par('usr')rect(usr[1],usr[3],nx+1,usr[4],border=NA,col='lemonchiffon')rect(nx1,usr[3],usr[2],usr[4],border=NA,col='lavender')abline(h= (-3:3)*2 , col ='gray', lty =3)polygon( c(nx1:lx,lx:nx1), c(lb,rev(ub)), col ='orange', lty=2,border=NA)lines(nx1:lx, lb , lty=2)lines(nx1:lx, ub , lty=2)lines(as.numeric(x), lwd=2)lines(nx1:lx, forecast$pred , lwd=2 , col ='white')box()
# Compact metric summarymetrics <-data.frame(Horizon =c("Short run (1:12)", paste0("Long run (", min(13, fx), ":", fx, ")"), "Full horizon"),MAPE =c(mean(perf.mape1[1:min(12, fx)]),if (fx >12) mean(perf.mape1[13:fx]) elseNA, perf.mape1[fx]),SMAPE =c(mean(perf.smape1[1:min(12, fx)]),if (fx >12) mean(perf.smape1[13:fx]) elseNA, perf.smape1[fx]),MASE =c(mean(perf.mase1[1:min(12, fx)]),if (fx >12) mean(perf.mase1[13:fx]) elseNA, perf.mase1[fx]),RMSE =c(mean(perf.rmse[1:min(12, fx)]),if (fx >12) mean(perf.rmse[13:fx]) elseNA, perf.rmse[fx]))cat("\nForecast error summary:\n")print(metrics, row.names =FALSE)cat("\nInterpretation guide:\n")cat("- MASE < 1 means improvement over a naive benchmark.\n")cat("- RMSE penalizes large forecast misses more strongly than MAPE/SMAPE.\n")cat("- High long-run uncertainty indicates widening prediction intervals.\n")cat("\nIllustrative probability outputs at final horizon:\n")cat("P(next value < previous value):", round(prob.dec[fx], 3), "\n")cat("P(next value < seasonal benchmark):", round(prob.sdec[fx], 3), "\n")cat("Two-sided tail probability of observed error:", round(2* (1- prob.pval[fx]), 3), "\n")
Forecast error summary:
Horizon MAPE SMAPE MASE RMSE
Short run (1:12) 0.02736250 0.02642595 0.2492757 17.86098
Long run (12:12) NA NA NA NA
Full horizon 0.02904855 0.02822404 0.2747444 18.59493
Interpretation guide:
- MASE < 1 means improvement over a naive benchmark.
- RMSE penalizes large forecast misses more strongly than MAPE/SMAPE.
- High long-run uncertainty indicates widening prediction intervals.
Illustrative probability outputs at final horizon:
P(next value < previous value): 0.071
P(next value < seasonal benchmark): 0.133
Two-sided tail probability of observed error: 0.633
153.2 Example: Births
The ARIMA forecast for Births yields:
the expected forecast uncertainty is small on the short run (2.7%) and on the long run (3.1%)
the actual forecast error is roughly equal to the expected error
the ceteris paribus conditions are not fully satisfied during the last 12 months (several months show actual births significantly different from forecast)
153.3 Example: Soldiers
The ARIMA forecast for Soldiers leads to:
the expected forecast uncertainty is large on the short run (+100%) and extremely high on the long run (+200%)
the actual forecast error is smaller than the expected error
the ceteris paribus conditions are not satisfied during the last 12 months because the withdrawal decision is an external intervention1
These uncertainty levels are a warning signal: even if point forecasts look acceptable, prediction intervals that wide indicate the pure ARIMA specification is inadequate for policy-relevant inference.
153.4 Example: Traffic
The ARIMA forecast for Traffic contains:
when \(\lambda = 1\) the expected forecast uncertainty is very high on the short run (99%) and extremely high on the long run (111%)
when \(\lambda = 0\) the expected forecast uncertainty is very high on the short run (139%) and extremely high on the long run (195%)
the actual forecast error is much smaller than the expected error
the ceteris paribus conditions are satisfied during the last 12 months if \(\lambda = 0\) (this is not the case when \(\lambda = 1\))
Note: the confidence interval with \(\lambda = 0\) is highly skewed to the right. On the other hand, it does not go below zero.
153.5 Beyond Ceteris Paribus
All the forecasts in this chapter assume that ceteris paribus conditions hold — no exceptional events occur during the forecast period. When this assumption is violated (as in the Soldiers example, where a political decision fundamentally changed the level of the series), the pure ARIMA forecast becomes unreliable.
The next chapters address this limitation. Chapter 154 shows how to incorporate known external events (such as the UK seatbelt law or the Iraq troop withdrawal) into the ARIMA framework. Chapter 155 introduces tools for measuring lead/lag relationships between two series, and Chapter 156 generalises this to continuous input variables that influence the series dynamically.
Hyndman, Rob J., and Anne B. Koehler. 2006. “Another Look at Measures of Forecast Accuracy.”International Journal of Forecasting 22 (4): 679–88. https://doi.org/10.1016/j.ijforecast.2006.03.001.
At this point we observe that the model is not providing the correct confidence interval (it is too wide and it goes below zero). An asymmetric confidence interval which correctly takes into account the fact that the American President decided to withdraw US troops from Iraq should be used instead of this ceteris paribus model.↩︎