Code
x <- seq(0,7,length=1000)
hx <- df(x, df1 = 8, df2 = 5)
plot(x, hx, type="l", xlab="X", ylab="f(X)", xlim=c(0,7), main="Fisher F density", sub = "(m = 8, n = 5)")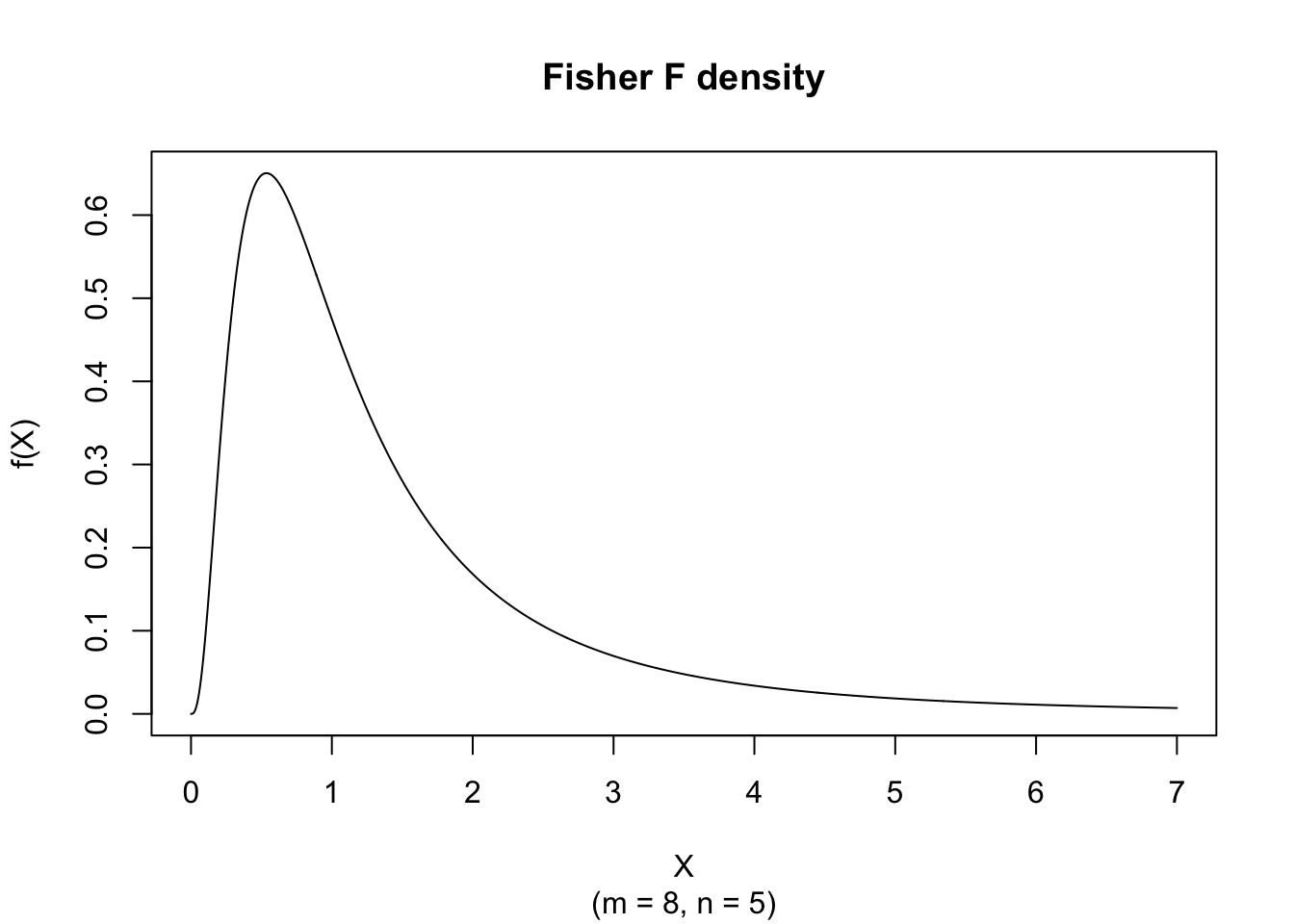
The random variate \(X\) defined for the range \(0 \leq X \leq +\infty\), is said to have an F-Distribution (i.e. \(X \sim \text{F} \left( m, n \right)\)) with shape parameters \(m, n \in \mathbb{N}^+\).
\[ f(X) = \frac{\left( \frac{m}{n} \right)^{\frac{m}{2}} X^{\frac{m}{2}-1} }{\text{B} \left[ \frac{m}{2}, \frac{n}{2} \right] \left[ 1 + \left( \frac{m}{n} \right) X \right]^{\frac{m+n}{2}} } \]
The figure below shows an example of the Fisher Probability Density function with \(m = 8\) and \(n = 5\).
x <- seq(0,7,length=1000)
hx <- df(x, df1 = 8, df2 = 5)
plot(x, hx, type="l", xlab="X", ylab="f(X)", xlim=c(0,7), main="Fisher F density", sub = "(m = 8, n = 5)")There is no elementary closed form of the Distribution Function; it is expressed exactly via the regularized incomplete beta function and computed by pf().
\[ \mu_j' = \left( \frac{n}{m} \right)^j \frac{\Gamma \left[ \frac{m}{2} + j \right] \Gamma \left[ \frac{n}{2} -j \right] }{\Gamma \left[ \frac{m}{2} \right] \Gamma \left[ \frac{n}{2} \right] } \]
for \(n > 2 j\).
\[ \text{E}(X) = \frac{n}{n-2} \]
for \(n > 2\).
\[ \text{V}(X) = \frac{2n^2 (m+n-2)}{m(n-2)^2(n-4)} \]
for \(n > 4\).
\[ \text{Mo}(X) = \frac{n}{m} \frac{m-2}{n+2} \]
for \(m > 2\).
\[ g_1 = \frac{(2m + n -2)}{(n-6)} \sqrt{\frac{8(n-4)}{m(m+n-2)}} \]
for \(n > 6\).
\[ g_2 = 3 + \frac{12 \left[m(5n-22)(m+n-2) + (n-4)(n-2)^2\right]}{m(n-6)(n-8)(m+n-2)} \]
for \(n > 8\).
\[ VC = \sqrt{\frac{2(m+n-2)}{m(n-4)}} \]
for \(n > 4\).
Random numbers from the F variate with \(m\) and \(n\) degrees of freedom, denoted by F\((m,n)\), can be computed by using the relationship between the F variate and two independent Chi-squared variates.
Let
\[ \begin{cases} \chi^2(m) \text{ denote a Chi-squared variate with m degrees of freedom} \\ \chi^2(n) \text{ denote a Chi-squared variate with n degrees of freedom} \\ \text{N}(0,1) \text{ denote a unit normal variate} \end{cases} \]
then
\[ \text{F}(m,n) \sim \frac{\frac{1}{m} \sum_{i=1}^{m}\text{N}_i(0,1)^2}{\frac{1}{n}\sum_{i=1}^{n}\text{N}_i(0,1)^2} = \frac{\frac{\chi^2(m)}{m}}{\frac{\chi^2(n)}{n}} \]
The first parameter, \(m\), does not affect the expected value.
As the degrees of freedom \(m\) and \(n\) increase, a suitably centered and scaled F\((m,n)\) variate approaches normality.
The inverse of an F variate with \(m\) and \(n\) degrees of freedom, denoted by F\((m,n)\), is also an F variate but with degrees of freedom \(n\) and \(m\), i.e.
\[ \text{F}(n,m) \sim \frac{1}{\text{F}(m,n)} \]
Suppose we compare two independent sample variances and obtain \(s_1^2/s_2^2 = 1.8\) with \((m,n)=(12,15)\). A right-tail probability is:
1 - pf(1.8, df1 = 12, df2 = 15)[1] 0.1405509The F-distribution is central to variance-ratio inference, including ANOVA, regression F-tests, and model-comparison procedures based on nested sums of squares.