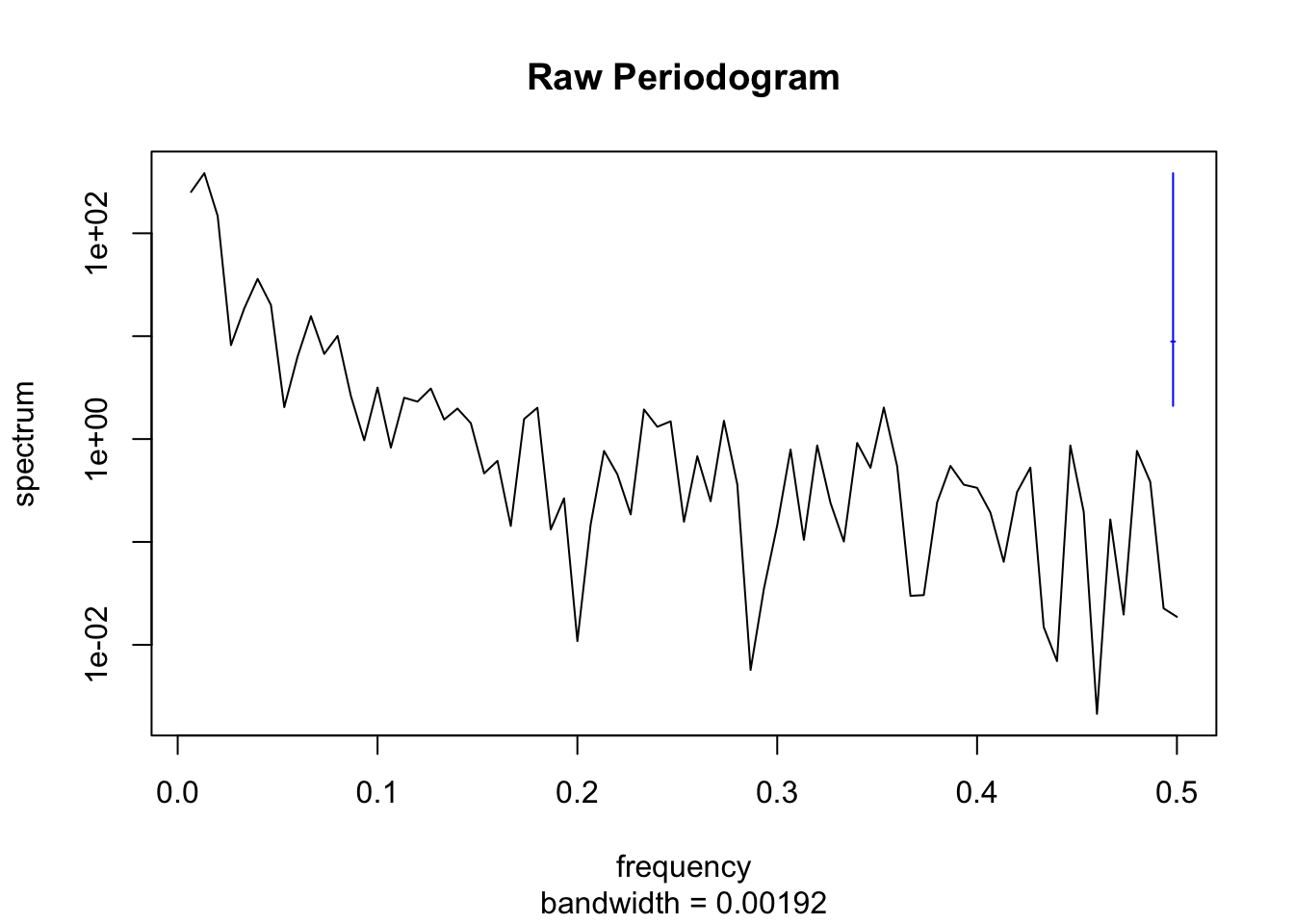
The Periodogram of a time series \(Y_t\) identifies the cyclical components that are present by computing a sinusoidal decomposition. Formally, we compute the squared correlation between the time series and cyclical waves of frequency \(\omega\) which leads to the Periodogram \(I(\omega)\)
which can be shown to be a mathematical transformation of the Autocorrelation Function. In other words, the ACF and the Periodogram contain the same information. This, however, does not imply that one should use only one technique: sometimes the ACF is easier to interpret and sometimes the Periodogram is easier. Also note, that one often applies a kernel function to obtain a smoothed estimator of the Periodogram.
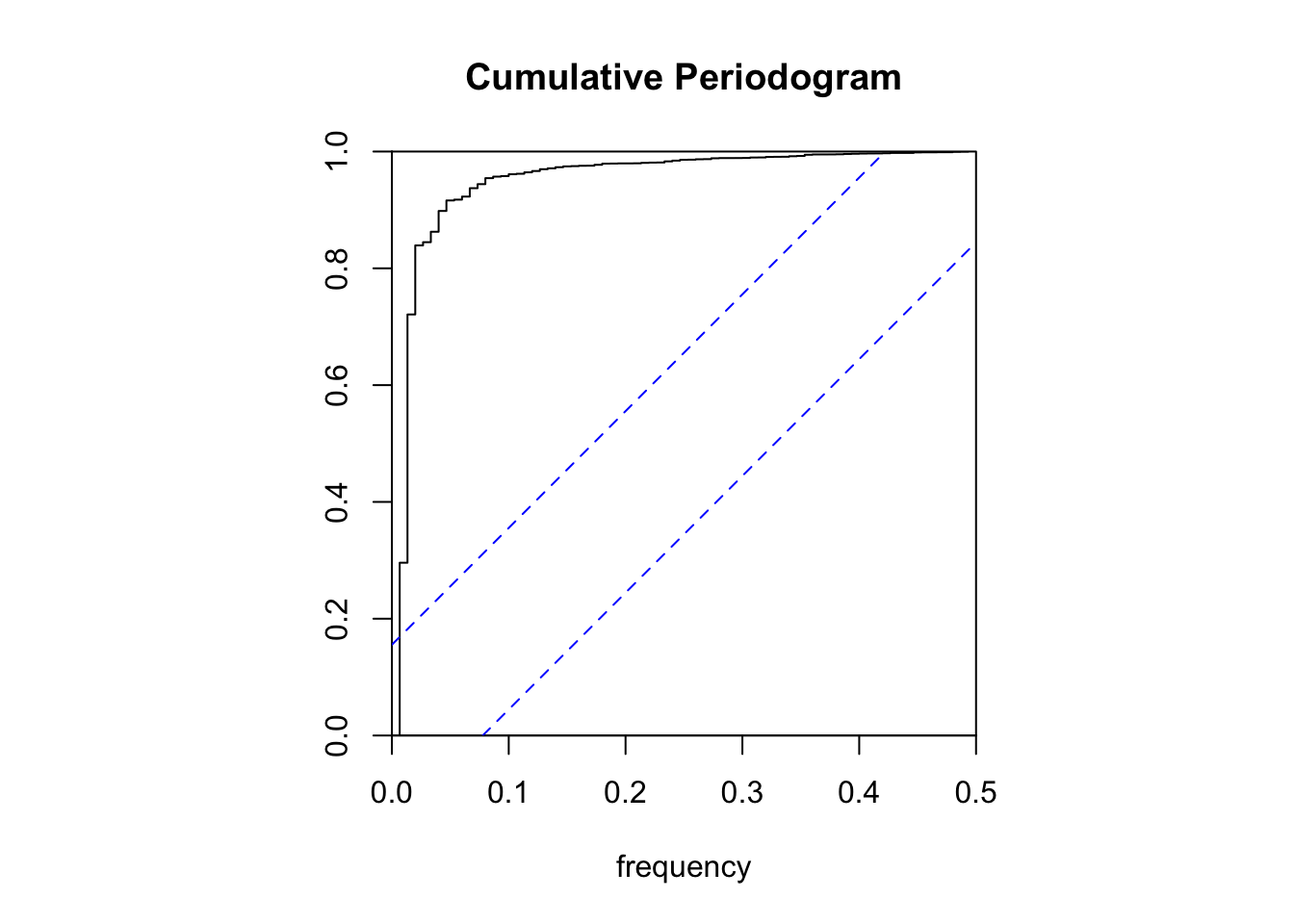
The Cumulative Periodogram \(U(\omega)\) is simply
The Cumulative Periodogram is also available on in RFC under the “Time Series / Spectral Analysis” menu item.
To compute the Cumulative Periodogram on your local machine, the following script can be used in the R console:
x <-100+cumsum(rnorm(150))summary(x)par1 =1#Box-Cox transformation parameter par2 =0#Degree (d) of non-seasonal differencing par3 =0#Degree (D) of seasonal differencing par4 =12#Seasonal Period if (par1 ==0) { x <-log(x)} else { x <- (x ^ par1 -1) / par1}if (par2 >0) x <-diff(x,lag=1,difference=par2)if (par3 >0) x <-diff(x,lag=par4,difference=par3)r <-spectrum(x,main='Raw Periodogram')
cpgram(x,main='Cumulative Periodogram')
Min. 1st Qu. Median Mean 3rd Qu. Max.
99.48 104.72 106.70 107.00 108.94 116.11
To compute the Cumulative Periodogram, the R code uses the standard spectrum and cpgram functions to compute the analysis.
93.3 Purpose
In practice, the Cumulative Periodogram can be used to:
describe/summarize the dynamical properties of time series
identify non-seasonal and seasonal trends
identify various types of typical patterns that correspond to well-known forecasting models
check the independence assumption of the residuals of regression and forecasting models
93.4 Pros & Cons
93.4.1 Pros
The Cumulative Periodogram has the following advantages:
It provides a lot of information about the dynamical properties of a time series.
With some practice, it is (generally speaking) easy to interpret.
93.4.2 Cons
The Cumulative Periodogram has the following disadvantages:
It cannot be computed with many software packages.
In many disciplines, readers are not familiar with this type of analysis.
93.5 Pedagogical example
Before turning to a real dataset, it is helpful to study the inverse problem. In the Fourier Builder app below, we specify the cyclical ingredients of a time series directly and then ask the periodogram and cumulative periodogram to recover them from the finished signal.
Start with the default Trend + seasonality preset and move between the Waves, Time series, and Diagnostics tabs. Several lessons become visible immediately:
increasing the amplitude of the 12-observation seasonal wave makes the peak near period 12 more dominant
adding harmonics at periods 6 and 4 creates extra peaks at those shorter seasonal frequencies
lengthening the long cycle beyond the sample length produces low-frequency power near the left edge of the periodogram, but not a perfectly resolved long-period peak because the sample does not contain a full cycle
The app is therefore pedagogically useful because it makes the frequency-domain logic concrete: we build a signal from known sine waves first, and the spectral tools then try to reconstruct those waves from the observed series.
For the best experience, open the app in a new tab. On many screens the handbook column is too narrow to display the control panel and the diagnostic panels comfortably side by side.
We now turn to a real-data example and consider the Airline Data. In a first step, we compute the Cumulative Periodogram (CP) for the original time series, i.e. without applying any differencing (\(d = D = 0\)).
The output shows that there are 6 frequencies where a peak of \(I(\omega)\) can be detected. The actual frequencies can be examined, in detail, in the accompanying table. The frequencies with peak spectrum values are: 0.0069, 0.0833, 0.1667, 0.25, 0.3333, and 0.4167. Since frequencies are simply the inverse of the period that is described by a cyclical wave, we can convert the frequencies into the following periods: 144, 12, 6, 4, 3, 2.4 (all expressed as months).
The information provided by the Periodogram is simply that the Airline time series can be essentially described as a long-run trend (i.e. a cycle with a period of 144 months) and the sum of five remaining cyclical waves which have a period of 12, 6, 4, 3, and 2.4 months respectively. All five of these remaining sine waves (i.e. 12, 6, 4, 3, and 2.4 months) describe a seasonal pattern because they fit exactly an integer number of times into one year (e.g. there are 5 cycles of the 2.4-month sine wave in one year). Hence the seasonal pattern of the Airline data can be described as the sum of five sine waves.
The plots of the analysis show exactly the same information. Let us look more closely at the Cumulative Periodogram which looks like a step function:
The first step corresponds to \(\omega = 0.0069\) and represents the long-run trend. This implies that we need to set \(d = 1\) if we wish to remove the trend.
The second step corresponds to \(\omega = 0.0833\) or, equivalently, \(\frac{1}{\omega} = 12\) which represents the 12 month cycle in the data. This is an indication that we should apply differencing with \(D = 1\) if we wish to remove the seasonal pattern.
The third step corresponds to \(\omega = 0.1667\) or, equivalently, \(\frac{1}{\omega} = 6\) which represents a 6 month cycle and which fits exactly twice in one year. Again, this is an indication that we should use differencing with \(D = 1\) if we wish to remove the seasonal pattern.
Steps four, five, and six represent sine wave of periods 4, 3 and 2.4 months, each of which fit perfectly in one year. Again, this indicates the presence of a seasonal pattern.
Since the \(U(\omega)\) is expressed as a normalized measure, we can interpret the steps of the Cumulative Periodogram in terms of the percentage of the Variability that is explained by the sine wave. The first step (i.e. the long-run trend) explains roughly 80% of the dynamical behavior of the time series (the first step as a height of 0.8). The combined effect of the first two sine waves (i.e. the long-run trend and the 12 month cycle) is more than 90%. This means that the 12 month cycle contributes about 10% to explaining the Variability of the time series. Similarly, the importance of each sine wave can be measured as the height of each step.
Now we compute the CP for \(d = 1\) and \(D = 0\) (set the slider accordingly). The output shows that the differenced time series does no longer exhibit a long-run trend (the first step has disappeared). The remaining steps are located in the same position as before but they are more clearly visible because the long-run trend is not dominating anymore.
It can be concluded that there is a strong seasonal pattern in the time series which can be removed by setting \(D = 1\). The output for \(d = D = 1\) shows that there are no big steps in the curve. This implies that there are no important sine waves anymore which are able to explain the differenced time series. The CP curve consists of very small step sizes which are (more or less) evenly distributed.
93.7 Task
Examine the monthly Divorces time series. Does this time series exhibit a long-run trend and/or strong form of seasonality?