ROC stands for Receiver Operating Characteristic. It is a method that evaluates the performance of binary classifiers across all possible classification thresholds. The method was originally developed in signal detection theory (Green and Swets 1966) (during World War II) for radar operators who needed to distinguish enemy aircraft from noise.
In previous chapters, we introduced the Confusion Matrix (Chapter 59) and various classification metrics including Sensitivity, Specificity, and the concepts of True Positives, True Negatives, False Positives, and False Negatives. These metrics were computed for a single, fixed classification threshold. ROC analysis extends this by examining how classifier performance changes as the threshold varies.
60.2 The Classification Threshold
Binary classifiers such as the Naive Bayes Classifier (Chapter 9) do not directly produce binary predictions. Instead, they produce probability scores — estimates of the probability that each observation belongs to the positive class. To convert these probabilities into binary predictions, we must choose a classification threshold.
The classification rule is simple: if the predicted probability P(positive) is greater than or equal to the threshold, we predict positive; otherwise, we predict negative.
The choice of threshold directly affects the balance between Sensitivity and Specificity:
Lowering the threshold makes the classifier more likely to predict positive. This increases Sensitivity (we catch more true positives) but decreases Specificity (we also generate more false positives).
Raising the threshold makes the classifier more conservative. This increases Specificity (fewer false alarms) but decreases Sensitivity (we miss more true positives).
There is no threshold that simultaneously maximizes both Sensitivity and Specificity. The choice of threshold depends on the relative costs of different types of errors.
This threshold-choice problem is an example of a more general idea used throughout this handbook: decision thresholds depend on purpose. In ROC analysis, we choose a classification threshold based on the trade-off between false positives and false negatives (and their costs). In hypothesis testing, the same logic reappears when choosing a significance threshold \(\alpha\). The general framework is discussed in Chapter 112.
60.2.2 Example: Fraud Detection
Continuing the fraud detection example from Chapter 58 and Chapter 59, suppose our Naive Bayes classifier produces the following probability scores for seven transactions:
Table 60.1: Fraud Probability Scores
Transaction
Actual Fraud
P(Fraud)
1
No
0.62
2
Yes
0.81
3
No
0.15
4
No
0.23
5
Yes
0.38
6
No
0.09
7
Yes
0.44
At threshold = 0.50:
Transactions 1 and 2 are predicted as fraud (P ≥ 0.50)
Transaction 2 is correctly identified (TP = 1), but transaction 1 is a false alarm (FP = 1)
Transactions 5 and 7 are missed (FN = 2)
At threshold = 0.35:
Transactions 1, 2, 5, and 7 are predicted as fraud
We catch more fraud (TP = 3) but still have a false alarm (FP = 1)
Transactions 5 (P = 0.38) and 7 (P = 0.44) are now additionally correctly identified
The confusion matrix changes with every threshold choice, and so do all the derived metrics.
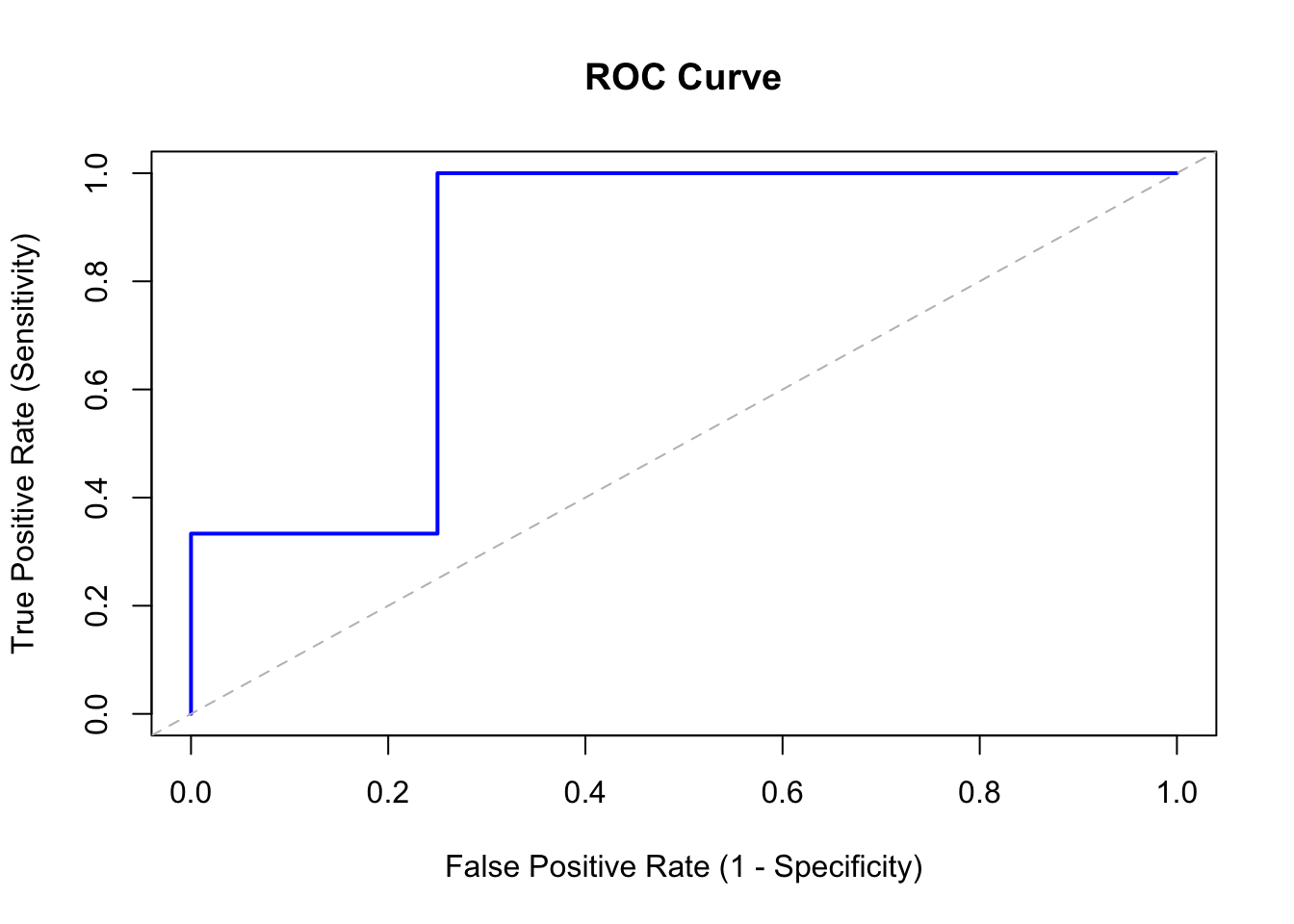
60.3 Constructing the ROC Curve
The ROC curve visualizes classifier performance across all possible thresholds. It is constructed as follows:
For each possible threshold value (from 0 to 1):
Classify all observations using that threshold
Compute the Confusion Matrix
Calculate the True Positive Rate (TPR = Sensitivity)
Calculate the False Positive Rate (FPR = 1 − Specificity)
Plot each (FPR, TPR) pair as a point
Connect the points to form the ROC curve
60.3.1 Interpreting the ROC Curve
The ROC curve is plotted with:
X-axis: False Positive Rate (FPR) ranging from 0 to 1
Y-axis: True Positive Rate (TPR) ranging from 0 to 1
Key reference points:
Bottom-left corner (0, 0): Threshold = 1.0. No positive predictions are made, so TPR = 0 and FPR = 0.
Top-right corner (1, 1): Threshold = 0.0. All predictions are positive, so TPR = 1 and FPR = 1.
Top-left corner (0, 1): Perfect classification. All positives are correctly identified (TPR = 1) with no false alarms (FPR = 0).
Diagonal line: Random guessing. A classifier with no discriminative ability produces points along the diagonal.
A good classifier produces an ROC curve that bows toward the top-left corner, staying well above the diagonal.
60.3.2 R Code for ROC Curve Construction
The following code demonstrates how to construct an ROC curve from scratch:
# Example data: predicted probabilities and actual outcomespredicted_prob <-c(0.62, 0.81, 0.15, 0.23, 0.38, 0.09, 0.44)actual <-c(0, 1, 0, 0, 1, 0, 1) # 1 = Fraud, 0 = No Fraud# Function to compute TPR and FPR at a given thresholdcompute_rates <-function(threshold, probs, actuals) { predictions <-as.integer(probs >= threshold) TP <-sum(predictions ==1& actuals ==1) FP <-sum(predictions ==1& actuals ==0) TN <-sum(predictions ==0& actuals ==0) FN <-sum(predictions ==0& actuals ==1) TPR <- TP / (TP + FN) # Sensitivity FPR <- FP / (FP + TN) # 1 - Specificityreturn(c(FPR = FPR, TPR = TPR))}# Compute ROC curve pointsthresholds <-seq(0, 1, by =0.01)roc_points <-t(sapply(thresholds, compute_rates,probs = predicted_prob,actuals = actual))# Plot ROC curveplot(roc_points[, "FPR"], roc_points[, "TPR"],type ="l", lwd =2, col ="blue",xlab ="False Positive Rate (1 - Specificity)",ylab ="True Positive Rate (Sensitivity)",main ="ROC Curve",xlim =c(0, 1), ylim =c(0, 1))abline(a =0, b =1, lty =2, col ="gray") # Diagonal reference line
For larger datasets and more sophisticated analysis, the pROC package provides comprehensive ROC functionality:
library(pROC)roc_obj <-roc(actual, predicted_prob)plot(roc_obj, main ="ROC Curve (pROC package)")
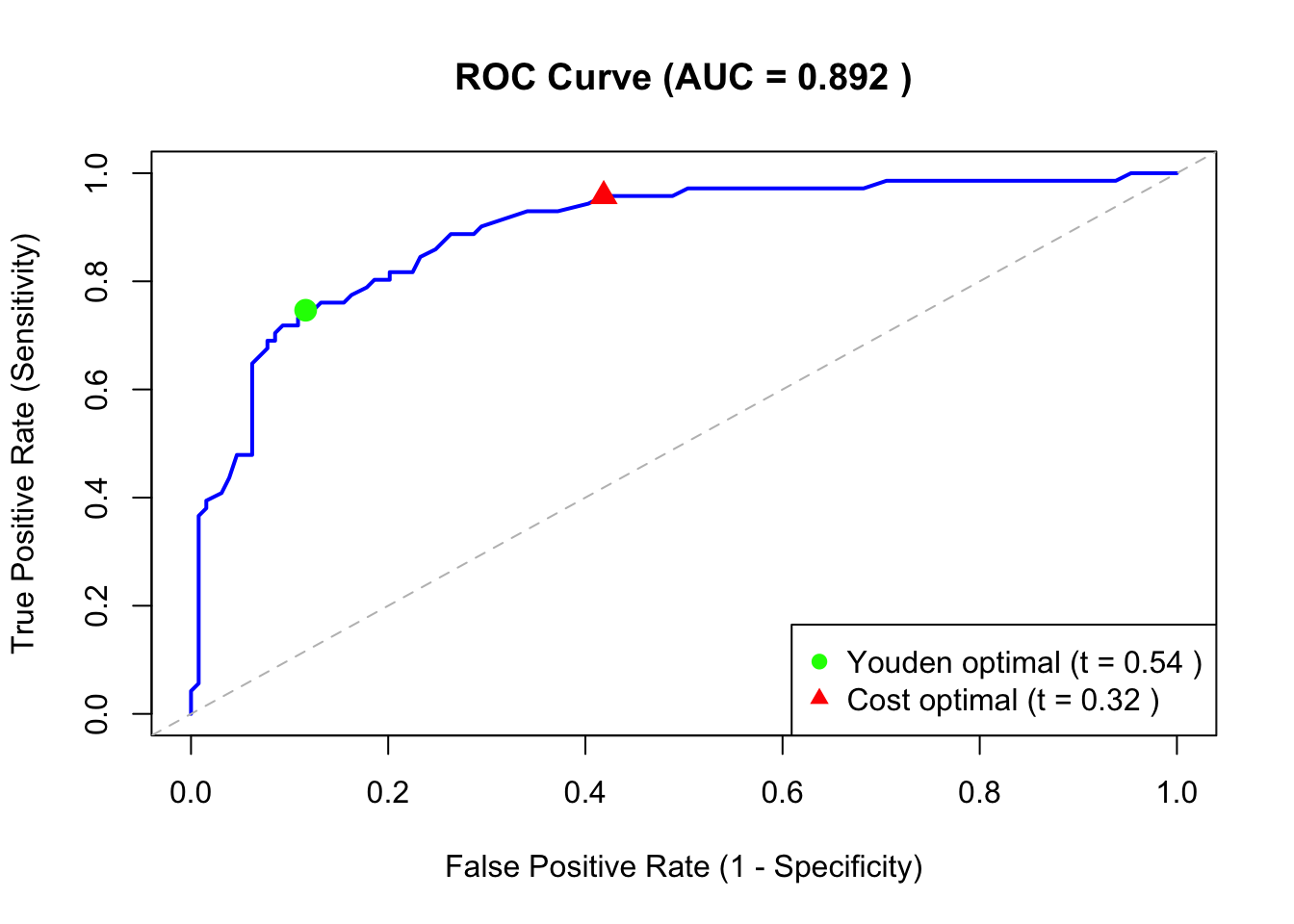
60.4 Area Under the Curve (AUC)
The Area Under the ROC Curve (AUC) provides a single summary measure of classifier performance across all thresholds.
60.4.1 Definition
The AUC has an intuitive probabilistic interpretation (Hanley and McNeil 1982): it represents the probability that the classifier will rank a randomly chosen positive instance higher than a randomly chosen negative instance.
An AUC of 0.5 indicates the classifier performs no better than random coin flipping. An AUC below 0.5 suggests the classifier is systematically wrong (predictions are inverted).
60.4.3 Connection to the Mann-Whitney U Statistic
The AUC is mathematically equivalent to the Mann-Whitney U statistic (normalized to [0, 1]), which was introduced in Chapter 121. This connection provides a non-parametric way to test whether a classifier’s AUC is significantly greater than 0.5.
60.4.4 Computing AUC in R
# Manual AUC computation using the trapezoidal rulecompute_auc <-function(fpr, tpr) {# Sort by FPR ord <-order(fpr) fpr <- fpr[ord] tpr <- tpr[ord]# Trapezoidal integrationsum(diff(fpr) * (head(tpr, -1) +tail(tpr, -1)) /2)}auc_value <-compute_auc(roc_points[, "FPR"], roc_points[, "TPR"])cat("AUC:", round(auc_value, 3), "\n")
AUC: 0.792
60.5 The Pay-off Matrix and Optimal Threshold Selection
While AUC summarizes overall discrimination ability, it does not tell us which threshold to use in practice. The optimal threshold depends on the costs and benefits of different classification outcomes.
60.5.1 The Pay-off Matrix
The pay-off matrix assigns economic values to each cell of the Confusion Matrix:
Table 60.3: The Pay-off Matrix
Actual Positive
Actual Negative
Predict Positive
Benefit(TP) or 0
Cost(FP)
Predict Negative
Cost(FN)
Benefit(TN) or 0
In many applications, we define the costs relative to correct classifications (which have zero cost), so the pay-off matrix simplifies to specifying:
Cost(FP): The cost of a false positive (false alarm)
Cost(FN): The cost of a false negative (missed detection)
60.5.2 Example: Fraud Detection Pay-offs
In fraud detection:
Cost(FN): A missed fraud means stolen funds must be reimbursed. Suppose this averages €500 per incident.
Cost(FP): A false alarm means a legitimate transaction is blocked, causing customer inconvenience and potential lost business. Suppose this costs €10 per incident.
The asymmetry is clear: missing a fraud is 50 times more costly than a false alarm. This should influence our threshold choice — we should be willing to accept more false alarms to catch more fraud.
60.5.3 Expected Cost at a Given Threshold
For a given threshold, the expected cost per classification is:
The optimal threshold maximizes \(J\). This is equivalent to finding the point on the ROC curve farthest from the diagonal. Note that Youden’s Index is identical to the Informedness metric introduced in Chapter 59.
60.5.4.2 Cost-based Optimization
When costs are known, the optimal threshold minimizes expected cost:
Observe that when false negatives are more costly than false positives, the cost-optimal threshold is lower than Youden’s optimal threshold. This makes the classifier more aggressive in predicting positives, increasing Sensitivity at the expense of Specificity.
60.8 ROC Analysis and p-values
The concept of p-values is formally introduced in Hypothesis Testing. In brief, a p-value answers the question: if the classifier is no better than random guessing, how likely would we be to observe results this extreme or more extreme? A small p-value (e.g., p < 0.05) suggests that the classifier has some discriminative ability that cannot be attributed to chance alone.
As explained in Chapter 112, the value \(\alpha\) is itself a decision threshold and should be chosen by the purpose of the analysis (confirmatory, diagnostic, exploratory/selection, or equivalence), not by a fixed convention alone. In the same spirit, ROC analysis makes threshold choice explicit by comparing classifier performance across many thresholds. A useful reporting strategy in both settings is to separate the observed result (e.g. p-value, AUC, ROC curve) from the decision threshold and, when appropriate, report decisions across a pre-declared set of thresholds.
However, the p-value does not tell us how well the classifier separates classes, which threshold should be used for classification, or what the consequences of different types of errors are. ROC analysis and the pay-off matrix address these questions directly.
Consider a fraud detection classifier. A p-value approach may conclude that the classifier performs significantly better than chance (p < 0.001) but this does not tell us whether the classifier is useful in practice. The AUC may reveal that the discrimination is modest (e.g. AUC = 0.65). When combined with a pay-off matrix, ROC analysis can identify the threshold that minimizes expected cost and thus directly supports the decision of whether (and how) to deploy the classifier.
Note that a classifier can be statistically significant (p < 0.001) but practically useless (AUC close to 0.52), or statistically non-significant (small sample) but practically valuable (AUC = 0.85), or have excellent discrimination (AUC = 0.95) but be economically suboptimal at the default threshold.
The three approaches answer different questions and should be used together:
Table 60.4: p-value, AUC, and Pay-off Approaches
Approach
Question
p-value
Is there evidence that the classifier is better than random?
AUC
How well does it discriminate?
ROC + Pay-off
What threshold should be used for classification?
60.9 Pros & Cons
60.9.1 Pros
ROC analysis has the following advantages:
The AUC summarizes performance across all thresholds, allowing fair comparison of classifiers regardless of their default settings.
The ROC curve provides a visualization of the Sensitivity-Specificity trade-off.
Combined with the pay-off matrix, ROC analysis can be used to select the classification threshold that minimizes expected cost.
ROC analysis evaluates how well a classifier ranks cases, independent of whether the probability scores are well-calibrated.
60.9.2 Cons
ROC analysis has the following disadvantages:
Real-world costs may be uncertain, vary across cases, or be difficult to quantify.
Standard ROC analysis assumes the cost of a false positive (or false negative) is the same for all cases, which may not hold in practice.
When the positive class is rare, the ROC curve may appear optimistic because even a small FPR translates to many false positives. The Precision-Recall curve (Davis and Goadrich 2006) is often preferred in such settings.
A classifier optimized for one prevalence may perform poorly if deployed where prevalence differs.
60.10 Task
Using the simulated fraud detection data or a dataset of your choice, compute the ROC curve and AUC. Interpret the AUC value.
Define a pay-off matrix appropriate for your application. How does the cost-optimal threshold differ from Youden’s optimal threshold?
Consider a scenario where the prevalence of fraud increases from 1% to 10%. How would this affect the optimal threshold? Use the expected cost formula to demonstrate.
Discuss: A classifier has p < 0.001 for the test that AUC > 0.5, but AUC = 0.53. Would you deploy this classifier? Why or why not?
Davis, Jesse, and Mark Goadrich. 2006. “The Relationship Between Precision-Recall and ROC Curves.”Proceedings of the 23rd International Conference on Machine Learning, 233–40. https://doi.org/10.1145/1143844.1143874.
Green, David M., and John A. Swets. 1966. Signal Detection Theory and Psychophysics. New York: John Wiley & Sons.
Hanley, James A., and Barbara J. McNeil. 1982. “The Meaning and Use of the Area Under a Receiver Operating Characteristic (ROC) Curve.”Radiology 143 (1): 29–36. https://doi.org/10.1148/radiology.143.1.7063747.
Hosmer, David W., and Stanley Lemeshow. 2000. Applied Logistic Regression. 2nd ed. New York: John Wiley & Sons.