x <- rnorm(200, 4, 10)
x <-sort(x)
i <- 0; f <- 0
q1 <- function(data,n,p,i,f) {
np <- n*p;
i <- floor(np)
f <- np - i
qvalue <- (1-f)*data[i] + f*data[i+1]
}
q2 <- function(data,n,p,i,f) {
np <- (n+1)*p
i <- floor(np)
f <- np - i
qvalue <- (1-f)*data[i] + f*data[i+1]
}
q3 <- function(data,n,p,i,f) {
np <- n*p
i <- floor(np)
f <- np - i
if (f==0) {
qvalue <- data[i]
} else {
qvalue <- data[i+1]
}
}
q4 <- function(data,n,p,i,f) {
np <- n*p
i <- floor(np)
f <- np - i
if (f==0) {
qvalue <- (data[i]+data[i+1])/2
} else {
qvalue <- data[i+1]
}
}
q5 <- function(data,n,p,i,f) {
np <- (n-1)*p
i <- floor(np)
f <- np - i
if (f==0) {
qvalue <- data[i+1]
} else {
qvalue <- data[i+1] + f*(data[i+2]-data[i+1])
}
}
q6 <- function(data,n,p,i,f) {
np <- n*p+0.5
i <- floor(np)
f <- np - i
qvalue <- data[i]
}
q7 <- function(data,n,p,i,f) {
# Definition 7 is algebraically identical to q2 in this implementation.
q2(data,n,p,i,f)
}
q8 <- function(data,n,p,i,f) {
np <- (n+1)*p
i <- floor(np)
f <- np - i
if (f==0) {
qvalue <- data[i]
} else {
if (f == 0.5) {
qvalue <- (data[i]+data[i+1])/2
} else {
if (f < 0.5) {
qvalue <- data[i]
} else {
qvalue <- data[i+1]
}
}
}
}
lx <- length(x)
qval <- array(NA,dim=c(99,8))
mystep <- 25
mystart <- 25
if (lx>10){
mystep=10
mystart=10
}
if (lx>20){
mystep=5
mystart=5
}
if (lx>50){
mystep=2
mystart=2
}
if (lx>=100){
mystep=1
mystart=1
}
for (perc in seq(mystart,99,mystep)) {
qval[perc,1] <- q1(x,lx,perc/100,i,f)
qval[perc,2] <- q2(x,lx,perc/100,i,f)
qval[perc,3] <- q3(x,lx,perc/100,i,f)
qval[perc,4] <- q4(x,lx,perc/100,i,f)
qval[perc,5] <- q5(x,lx,perc/100,i,f)
qval[perc,6] <- q6(x,lx,perc/100,i,f)
qval[perc,7] <- q7(x,lx,perc/100,i,f)
qval[perc,8] <- q8(x,lx,perc/100,i,f)
}
mydf = data.frame(`WA Xnp` = qval[,1],
`WA X(n+1)p` = qval[,2],
`EDF` = qval[,3],
`EDF Av` = qval[,4],
`EDF Int` = qval[,5],
`Cl Obs` = qval[,6],
`TBasic` = qval[,7],
`Excel` = qval[,8]
)
rownames(mydf) = seq(mystart,99,mystep) / 100
mydf
# we only plot the values for the fifth definition
plot(rownames(mydf), mydf[,5], xlab = "quantile", ylab = "value", main = "Quantiles (definition 5)")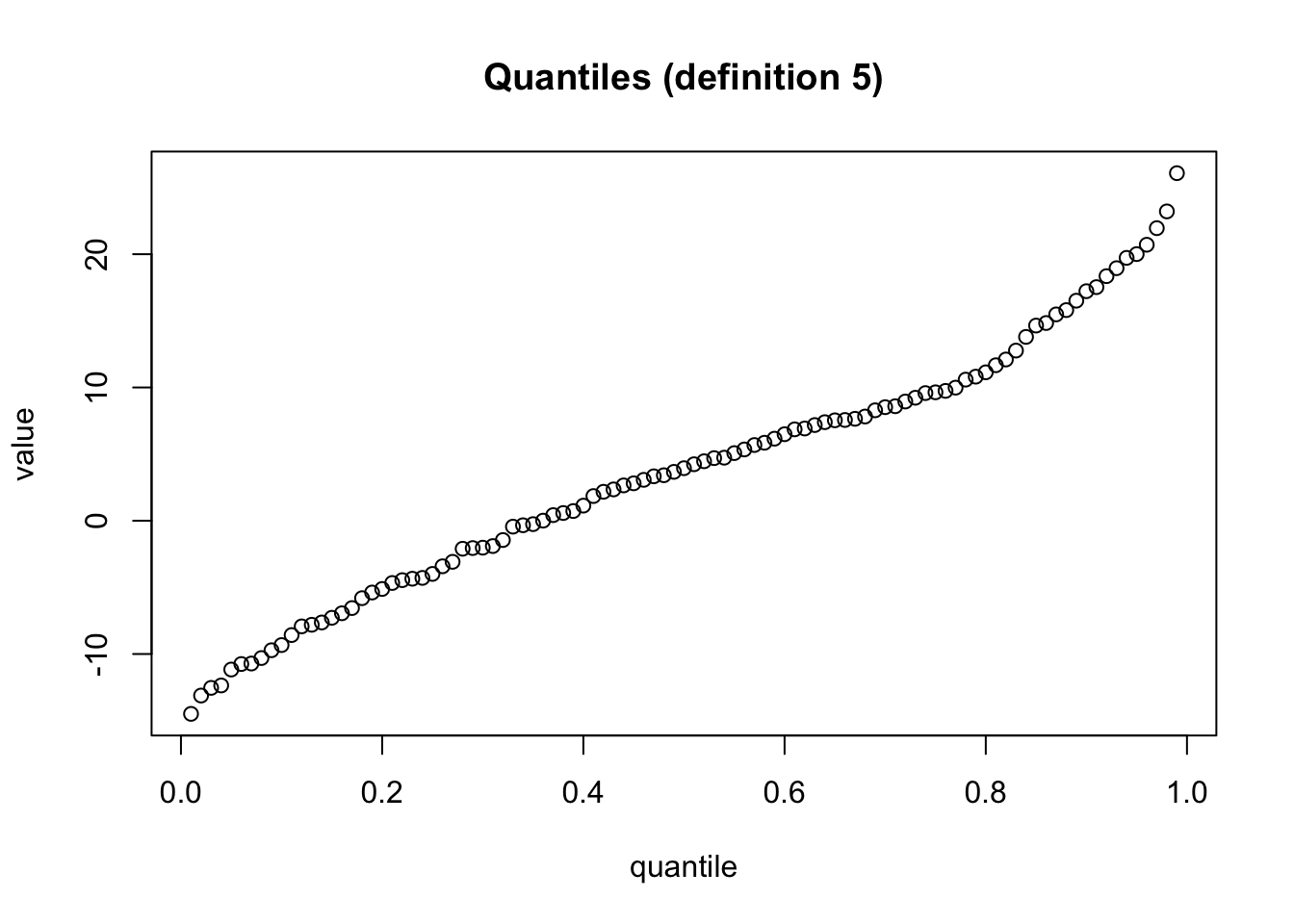
WA.Xnp WA.X.n.1.p EDF EDF.Av EDF.Int Cl.Obs TBasic Excel
0.01 -16.715924561 -16.693461396 -16.715924561 -15.592766323 -14.492071250 -16.715924561 -16.693461396 -16.715924561
0.02 -13.921877924 -13.905445098 -13.921877924 -13.511057275 -13.116669452 -13.921877924 -13.905445098 -13.921877924
0.03 -12.990746726 -12.976840702 -12.990746726 -12.758979659 -12.541118616 -12.990746726 -12.976840702 -12.990746726
0.04 -12.425890517 -12.423175081 -12.425890517 -12.391947571 -12.360720062 -12.425890517 -12.423175081 -12.425890517
0.05 -11.543116818 -11.523204555 -11.543116818 -11.343994194 -11.164783833 -11.543116818 -11.523204555 -11.543116818
0.06 -10.797452777 -10.794539214 -10.797452777 -10.773173085 -10.751806957 -10.797452777 -10.794539214 -10.797452777
0.07 -10.720463487 -10.720066749 -10.714795801 -10.714795801 -10.715192539 -10.720463487 -10.720066749 -10.720463487
0.08 -10.354458781 -10.349953778 -10.354458781 -10.326302512 -10.302651245 -10.354458781 -10.349953778 -10.354458781
0.09 -9.772542050 -9.767058218 -9.772542050 -9.742076314 -9.717094410 -9.772542050 -9.767058218 -9.772542050
0.1 -9.369567606 -9.365150847 -9.369567606 -9.347483809 -9.329816772 -9.369567606 -9.365150847 -9.369567606
0.11 -8.821270192 -8.791241887 -8.821270192 -8.684777897 -8.578313906 -8.821270192 -8.791241887 -8.821270192
0.12 -8.111435216 -8.086310239 -8.111435216 -8.006747814 -7.927185389 -8.111435216 -8.086310239 -8.111435216
0.13 -7.824599510 -7.821713499 -7.824599510 -7.813499467 -7.805285436 -7.824599510 -7.821713499 -7.824599510
0.14 -7.773803200 -7.750871169 -7.610002978 -7.610002978 -7.632935009 -7.773803200 -7.750871169 -7.773803200
0.15 -7.532997179 -7.488768463 -7.532997179 -7.385568124 -7.282367785 -7.532997179 -7.488768463 -7.532997179
0.16 -6.946385845 -6.945916420 -6.946385845 -6.944918890 -6.943921360 -6.946385845 -6.945916420 -6.946385845
0.17 -6.779704721 -6.733214473 -6.779704721 -6.642968698 -6.552722922 -6.779704721 -6.733214473 -6.779704721
0.18 -6.246236560 -6.150742431 -6.246236560 -5.980975091 -5.811207750 -6.246236560 -6.150742431 -6.246236560
0.19 -5.502187811 -5.474957130 -5.502187811 -5.430528125 -5.386099121 -5.502187811 -5.474957130 -5.502187811
0.2 -5.164710111 -5.153497897 -5.164710111 -5.136679575 -5.119861254 -5.164710111 -5.153497897 -5.164710111
0.21 -4.671390475 -4.671328835 -4.671390475 -4.671243714 -4.671158593 -4.671390475 -4.671328835 -4.671390475
0.22 -4.548527868 -4.522841881 -4.548527868 -4.490150625 -4.457459368 -4.548527868 -4.522841881 -4.548527868
0.23 -4.388516828 -4.377457822 -4.388516828 -4.364475510 -4.351493199 -4.388516828 -4.377457822 -4.388516828
0.24 -4.316096124 -4.307551751 -4.316096124 -4.298295348 -4.289038944 -4.316096124 -4.307551751 -4.316096124
0.25 -4.079947130 -4.050063929 -4.079947130 -4.020180727 -3.990297525 -4.079947130 -4.050063929 -4.079947130
0.26 -3.473246638 -3.454072144 -3.473246638 -3.436372611 -3.418673078 -3.473246638 -3.454072144 -3.473246638
0.27 -3.245534137 -3.185150290 -3.245534137 -3.133712197 -3.082274105 -3.245534137 -3.185150290 -3.245534137
0.28 -2.168810651 -2.142745273 -2.075720015 -2.075720015 -2.101785393 -2.168810651 -2.142745273 -2.168810651
0.29 -2.070811903 -2.062411466 -2.070811903 -2.070811903 -2.050245315 -2.070811903 -2.062411466 -2.070811903
0.3 -2.037002697 -2.030136898 -2.037002697 -2.025559699 -2.020982500 -2.037002697 -2.030136898 -2.037002697
0.31 -1.965890486 -1.936065016 -1.965890486 -1.917784889 -1.899504762 -1.965890486 -1.936065016 -1.965890486
0.32 -1.605320572 -1.531190675 -1.605320572 -1.489492609 -1.447794542 -1.605320572 -1.531190675 -1.605320572
0.33 -0.596281505 -0.520885436 -0.596281505 -0.482045036 -0.443204637 -0.596281505 -0.520885436 -0.596281505
0.34 -0.366486036 -0.352071155 -0.366486036 -0.345287682 -0.338504209 -0.366486036 -0.352071155 -0.366486036
0.35 -0.274901821 -0.263945769 -0.274901821 -0.259250318 -0.254554867 -0.274901821 -0.263945769 -0.274901821
0.36 0.003113984 0.005607992 0.003113984 0.006577884 0.007547776 0.003113984 0.005607992 0.003113984
0.37 0.387715771 0.407663617 0.387715771 0.414672320 0.421681022 0.387715771 0.407663617 0.387715771
0.38 0.562667464 0.572921674 0.562667464 0.576159845 0.579398017 0.562667464 0.572921674 0.562667464
0.39 0.715495338 0.723665852 0.715495338 0.725970356 0.728274860 0.715495338 0.723665852 0.715495338
0.4 1.087178826 1.117467457 1.087178826 1.125039614 1.132611772 1.087178826 1.117467457 1.087178826
0.41 1.695679153 1.804477258 1.695679153 1.828359768 1.852242279 1.695679153 1.804477258 1.695679153
0.42 2.111192091 2.155906470 2.111192091 2.164423494 2.172940519 2.111192091 2.155906470 2.111192091
0.43 2.320818520 2.343886327 2.320818520 2.347641551 2.351396776 2.320818520 2.343886327 2.320818520
0.44 2.649583267 2.650795273 2.649583267 2.650960546 2.651125820 2.649583267 2.650795273 2.649583267
0.45 2.764758649 2.800098936 2.764758649 2.804025635 2.807952333 2.764758649 2.800098936 2.764758649
0.46 3.064414063 3.068369148 3.064414063 3.068713068 3.069056988 3.064414063 3.068369148 3.064414063
0.47 3.287773621 3.328490813 3.287773621 3.331089783 3.333688753 3.287773621 3.328490813 3.287773621
0.48 3.387892659 3.412686920 3.387892659 3.413720014 3.414753108 3.387892659 3.412686920 3.387892659
0.49 3.642843405 3.667090476 3.642843405 3.667585314 3.668080152 3.642843405 3.667090476 3.642843405
0.5 3.807705059 3.942983017 3.807705059 3.942983017 3.942983017 3.807705059 3.942983017 3.942983017
0.51 4.170923434 4.241254812 4.170923434 4.239875766 4.238496719 4.170923434 4.241254812 4.308828097
0.52 4.346172112 4.472752829 4.346172112 4.467884340 4.463015851 4.346172112 4.472752829 4.589596568
0.53 4.695779951 4.698863844 4.695779951 4.698689284 4.698514724 4.695779951 4.698863844 4.701598618
0.54 4.727270028 4.732293447 4.727270028 4.731921341 4.731549236 4.727270028 4.732293447 4.736572655
0.55 4.957652788 5.101049997 5.218374986 5.218374986 5.074977777 4.957652788 5.101049997 5.218374986
0.56 5.242431464 5.378200080 5.484875421 5.484875421 5.349106805 5.242431464 5.378200080 5.484875421
0.57 5.645387992 5.692783612 5.645387992 5.645387992 5.681142582 5.645387992 5.692783612 5.728538202
0.58 5.728904793 5.899060536 5.728904793 5.728904793 5.852121021 5.728904793 5.899060536 6.022276763
0.59 6.027017982 6.214433608 6.027017982 6.185844784 6.157255959 6.027017982 6.214433608 6.344671586
0.6 6.453739001 6.510850163 6.453739001 6.501331636 6.491813109 6.453739001 6.510850163 6.548924271
0.61 6.855828556 6.856560901 6.855828556 6.856428839 6.856296776 6.855828556 6.856560901 6.857029121
0.62 6.875313507 6.950495481 6.875313507 6.935944132 6.921392782 6.875313507 6.950495481 6.996574756
0.63 7.150261074 7.199864021 7.150261074 7.189628492 7.179392964 7.150261074 7.199864021 7.228995910
0.64 7.326055742 7.450529801 7.326055742 7.423301100 7.396072400 7.326055742 7.450529801 7.520546459
0.65 7.535425755 7.537496188 7.535425755 7.537018396 7.536540603 7.535425755 7.537496188 7.538611036
0.66 7.541473093 7.579733114 7.541473093 7.570457958 7.561182801 7.541473093 7.579733114 7.599442822
0.67 7.647253779 7.650758407 7.647253779 7.649869173 7.648979939 7.647253779 7.650758407 7.652484566
0.68 7.785682996 7.857408696 7.785682996 7.838422482 7.819436267 7.785682996 7.857408696 7.891161967
0.69 8.203210964 8.387360780 8.203210964 8.336652859 8.285944939 8.203210964 8.387360780 8.470094755
0.7 8.513693104 8.530572444 8.513693104 8.525749775 8.520927107 8.513693104 8.530572444 8.537806447
0.71 8.566152935 8.630305832 8.566152935 8.611331032 8.592356231 8.566152935 8.630305832 8.656509129
0.72 8.879994050 9.048284497 8.879994050 8.996862416 8.945440335 8.879994050 9.048284497 9.113730782
0.73 9.128040100 9.399984864 9.128040100 9.314303637 9.228622410 9.128040100 9.399984864 9.500567174
0.74 9.569823392 9.592319924 9.569823392 9.585023751 9.577727579 9.569823392 9.592319924 9.600224110
0.75 9.630714864 9.649418237 9.630714864 9.643183779 9.636949321 9.630714864 9.649418237 9.655652694
0.76 9.681168708 9.881360937 9.681168708 9.812874122 9.744387307 9.681168708 9.881360937 9.944579535
0.77 9.962688185 10.042186100 9.962688185 10.014310208 9.986434316 9.962688185 10.042186100 10.065932231
0.78 10.561454903 10.655507187 10.561454903 10.621744828 10.587982470 10.561454903 10.655507187 10.682034754
0.79 10.785551276 10.881821465 10.785551276 10.846481776 10.811142086 10.785551276 10.881821465 10.907412275
0.8 11.084823027 11.297186395 11.084823027 11.217550132 11.137913869 11.084823027 11.297186395 11.350277236
0.81 11.597064341 11.897233740 11.597064341 11.782354094 11.667474447 11.597064341 11.897233740 11.967643846
0.82 12.004520977 12.432263444 12.004520977 12.265339555 12.098415665 12.004520977 12.432263444 12.526158132
0.83 12.698592002 13.038596291 12.698592002 12.903413863 12.768231435 12.698592002 13.038596291 13.108235724
0.84 13.765011713 13.925287483 13.765011713 13.860413957 13.795540431 13.765011713 13.925287483 13.955816201
0.85 14.629557590 14.713481248 14.629557590 14.678924448 14.644367648 14.629557590 14.713481248 14.728291305
0.86 14.835971872 14.836235663 14.835971872 14.836125239 14.836014815 14.835971872 14.836235663 14.836278605
0.87 15.450384890 15.663322229 15.450384890 15.572762671 15.482203113 15.450384890 15.663322229 15.695140452
0.88 15.758680926 16.098548681 15.758680926 15.951787605 15.805026529 15.758680926 16.098548681 16.144894284
0.89 16.474240831 16.775425681 16.474240831 16.643445803 16.511465924 16.474240831 16.775425681 16.812650775
0.9 17.210435197 17.337557215 17.210435197 17.281058541 17.224559866 17.210435197 17.337557215 17.351681884
0.91 17.458258095 18.177340497 17.458258095 17.853358316 17.529376134 17.458258095 18.177340497 18.248458537
0.92 18.324252415 18.653534223 18.324252415 18.503209919 18.352885616 18.324252415 18.653534223 18.682167424
0.93 18.894348589 19.641181839 18.894348589 19.295871841 18.950561844 18.894348589 19.641181839 19.697395094
0.94 19.722272701 19.785473645 19.722272701 19.755890224 19.726306804 19.722272701 19.785473645 19.789507747
0.95 19.972394824 20.645310631 19.972394824 20.326561038 20.007811445 19.972394824 20.645310631 20.680727253
0.96 20.694155217 21.048210896 20.694155217 20.878559217 20.708907537 20.694155217 21.048210896 21.062963216
0.97 21.942717090 22.319577346 21.942717090 22.136974954 21.954372561 21.942717090 22.319577346 22.331232818
0.98 23.166258382 25.369776217 23.166258382 24.290502175 23.211228133 23.166258382 25.369776217 25.414745968
0.99 26.068333020 27.283915778 26.068333020 26.682263706 26.080611634 26.068333020 27.283915778 27.296194392