Code
x <- seq(0,9,length=1000)
hx <- dunif(x, min = 3, max = 6)
plot(x,hx,type="n",xlab="X", ylab="f(X)", xlim=c(0,9), main="Uniform density (a = 3 and b = 6)")
segments(x[-length(x)],hx[-length(x)],x[-1],hx[-length(x)])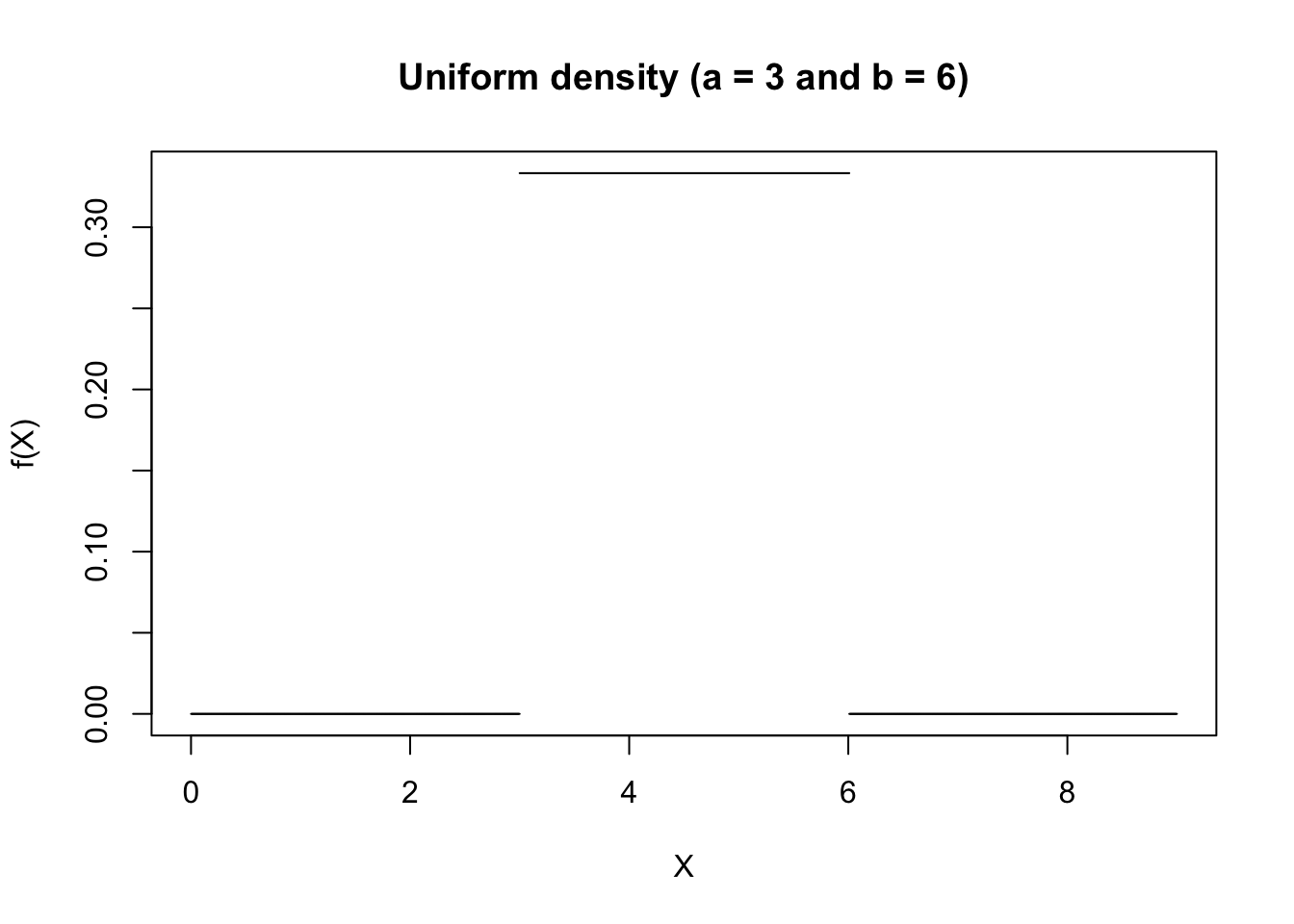
The random variate \(X\) defined for the range \(a \leq X \leq b\), is said to have a Uniform Distribution (i.e. \(X \sim \text{U}\left( a, b \right)\)) with location parameters \(a\) and \(b\) where \(-\infty < a < b < + \infty\)
\[ \begin{align*} \begin{cases} \text{f}(X) = \frac{1}{b-a} \text{ for } X \in [a, b] \\ \text{f}(X) = 0 \text{ for } X \notin [a, b] \end{cases} \end{align*} \]
The figure below shows an example of the Uniform Probability Density function for \(a = 3\) and \(b = 6\).
x <- seq(0,9,length=1000)
hx <- dunif(x, min = 3, max = 6)
plot(x,hx,type="n",xlab="X", ylab="f(X)", xlim=c(0,9), main="Uniform density (a = 3 and b = 6)")
segments(x[-length(x)],hx[-length(x)],x[-1],hx[-length(x)])Since the surface under the density function is (by definition) always equal to 1, it follows that the probability in the density figure below of \(X\) being contained in the interval \([a = 3, b = 6]\) is also equal to 1 (i.e. \(\text{P}(3 < X < 6) = 1\)).
\[ \begin{align*} \begin{cases} \text{F}(X) = 0 \text{ for } X < a \\ \text{F}(X) = \frac{X-a}{b-a} \text{ for } X \in [a, b] \\ \text{F}(X) = 1 \text{ for } X > b \end{cases} \end{align*} \]
The figure below shows an example of the Uniform Distribution function for \(a = 3\) and \(b = 6\).
x <- seq(0,9,length=1000)
hx <- punif(x, min = 3, max = 6)
plot(x, hx, type="l", xlab="X", ylab="F(X)", xlim=c(0,9), main="Uniform distribution (a = 3 and b = 6)")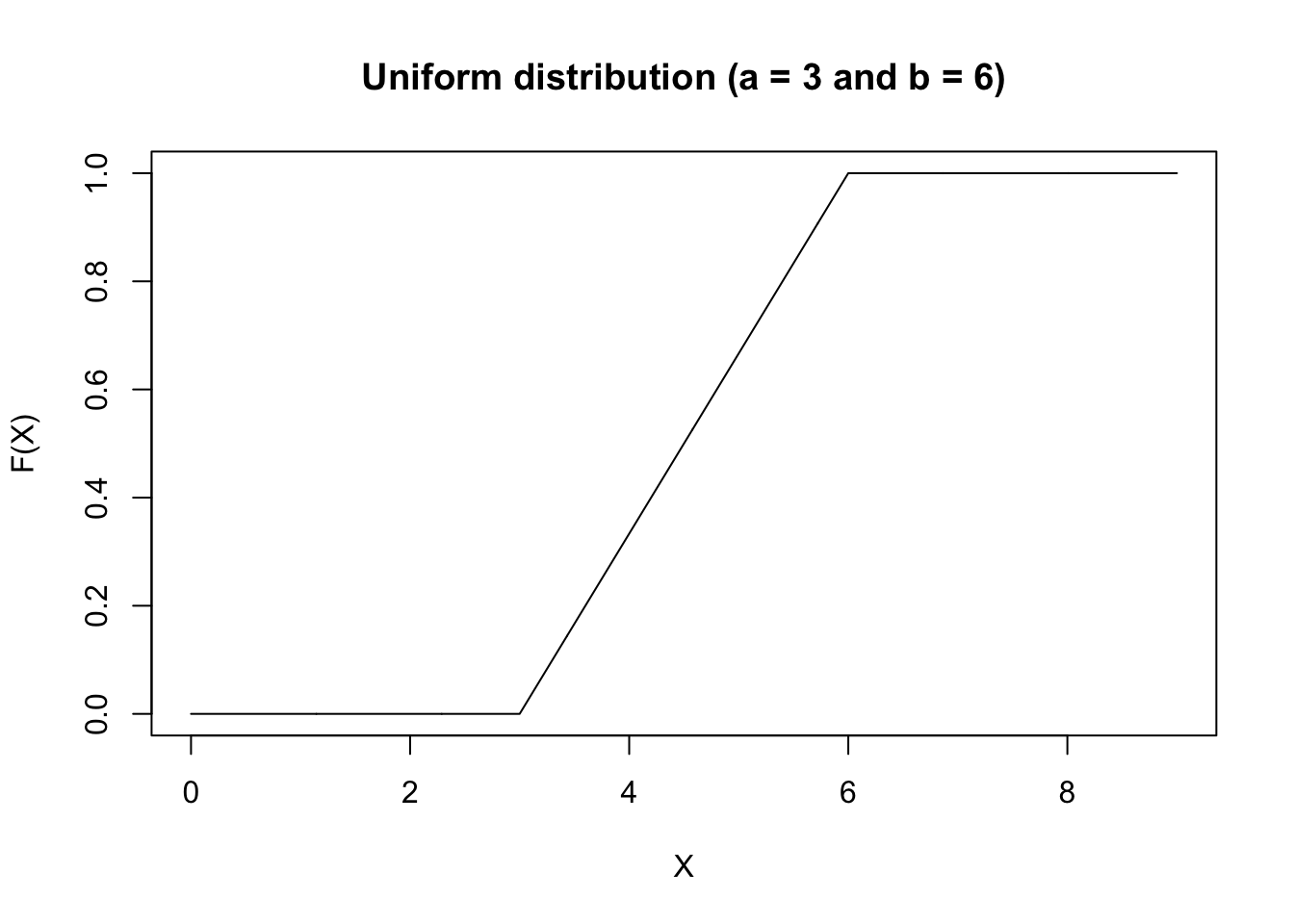
\[ \begin{align*} \begin{cases} M_X(t) = \frac{e^{bt} - e^{at}}{t(b-a)} \text{ for } t \neq 0 \\ M_X(t) = 1 \text{ for } t = 0 \\ \end{cases} \end{align*} \]
\[ \mu_j = 0 \text{ if $j$ is odd} \]
\[ \mu_j = \frac{(b-a)^j}{2^j(j+1)} \text{ if $j$ is even} \]
\[ \text{E}(X) = \frac{a+b}{2} \]
\[ \text{V}(X) = \frac{(b-a)^2}{12} \]
\[ \text{Med}(X) = \frac{a+b}{2} \]
\[ g_1 = 0 \]
\[ g_2 = \frac{9}{5} \]
\[ VC = \frac{1}{\sqrt{3}} \frac{b-a}{a+b} \]
There are several random processes (such as most random sampling processes) which can be assumed to have a Uniform Distribution. The Uniform Distribution has important applications because it is used in the generation of pseudo random numbers in digital computers. In addition, it is typically used in situations when investigating the probability that an event occurs within a specified time frame while there is no systematic cause to be found (e.g. a random error occurs in an assembly line production process -- if there’s no systematic reason for the error, we assume that there is an equal probability of the error occurring between times a and b).
Suppose we want to simulate the occurrence \(X\) of three mutually exclusive events \(X = A\), \(X = B\), and \(X = C\) with known probabilities that sum to 1. The event probabilities themselves are not “uniform”; instead, we use a Uniform random number generator on \([0,1]\) as a simulation mechanism. Since probabilities are conventionally bounded between 0 and 1, we set \(a = 0\) and \(b = 1\) to obtain
\[ \begin{align*} \begin{cases} \text{f}(X) = \frac{1}{1-0} \text{ for } X \in [0, 1] \\ \text{f}(X) = 0 \text{ for } X \notin [0, 1] \end{cases} \end{align*} \]
In other words, every random number that is produced by the digital computer lies between 0 and 1 with a probability of 100%. Now we can subdivide the interval \([0, 1]\) into three segments which correspond to the probabilities of each event. If, for instance, P(\(X = A\)) = 0.1, P(\(X = B\)) = 0.5, and P(\(X = C\)) = 0.4 then we can use the following rules to simulate events
\[ \begin{align*} \begin{cases} \text{P}(X = A) \text{ if } X \in [0, 0.1] \\ \text{P}(X = B) \text{ if } X \in \text{ } ]0.1, 0.6] \\ \text{P}(X = C) \text{ if } X \in \text{ } ]0.6, 1] \end{cases} \end{align*} \]
It is easy to generate random numbers from a Uniform Distribution in R. In our example we can do this as follows:
set.seed(42) # set random seed to make the result reproducible
random_events = rep("A", 100) # start with 100 events "A"
random_numbers = runif(n = 100, min = 0, max = 1) # draw 100 random numbers from U(0,1)
random_events[random_numbers > 0.1] = "B" # change all events to "B" if the random number > 0.1
random_events[random_numbers > 0.6] = "C" # change all events to "C" if the random number > 0.6
print(random_events) # print all random events
table(random_events) # frequency table [1] "C" "C" "B" "C" "C" "B" "C" "B" "C" "C" "B" "C" "C" "B" "B" "C" "C" "B"
[19] "B" "B" "C" "B" "C" "C" "A" "B" "B" "C" "B" "C" "C" "C" "B" "C" "A" "C"
[37] "A" "B" "C" "C" "B" "B" "A" "C" "B" "C" "C" "C" "C" "C" "B" "B" "B" "C"
[55] "A" "C" "C" "B" "B" "B" "C" "C" "C" "B" "C" "B" "B" "C" "C" "B" "A" "B"
[73] "B" "B" "B" "C" "A" "B" "B" "A" "B" "B" "B" "C" "C" "B" "B" "A" "A" "B"
[91] "C" "A" "B" "C" "C" "C" "B" "B" "C" "C"
random_events
A B C
11 43 46