Entropy is often referred to as the amount of information that is contained in an object (or the amount of disorder in a physical system):
In applied statistics, concentration measures are used to quantify how unevenly totals are distributed across categories (for example market shares, income shares, or portfolio weights). A low concentration means shares are spread out; a high concentration means a few categories dominate.
\[ H = - \sum_{i=1}^{n} p_i \ln p_i \]
where \(0 \leq H \leq \ln n\), \(p_i = \frac{x_i}{X}\), and \(X = \sum_{i=1}^{n} x_i\).
For the Gini formulas below, the observations must be ordered in nondecreasing order, i.e. \(x_{(1)} \leq x_{(2)} \leq \cdots \leq x_{(n)}\) (so \(x_i\) denotes the \(i^{\text{th}}\) ordered value).
For Definitions 3 and 4, the shares \(p_i\) (equivalently the values \(x_i\)) must be in nondecreasing order before computing the cumulative shares \(v_i\).
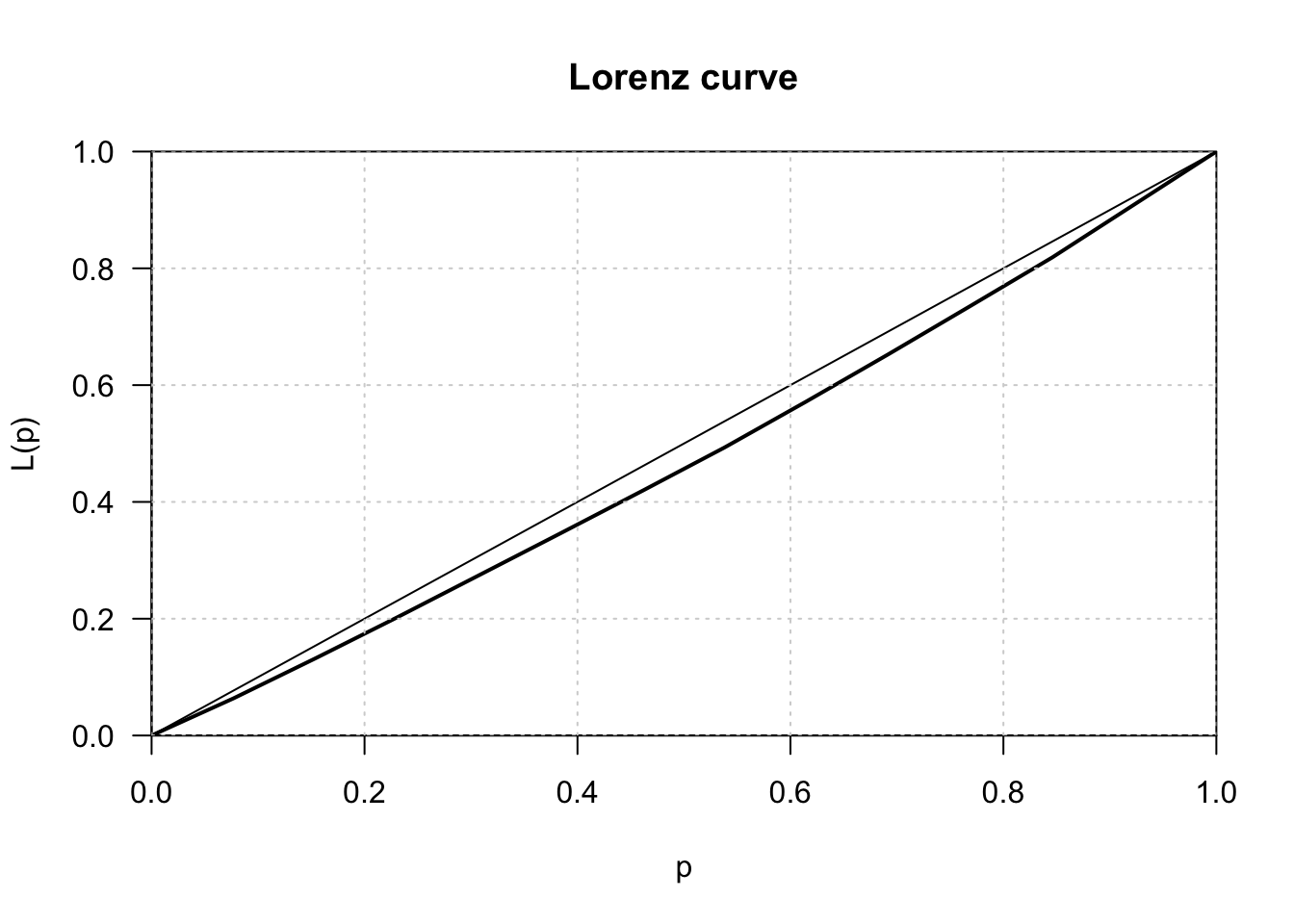
There is a relationship between the Gini Coefficient and the Lorenz Curve (Lorenz 1905) which is the graphical representation of the cumulative distribution of wealth or income (typically one represents the % of households on the horizontal axis and the % of income on the vertical axis).
Here again, the cumulative shares \(v_i\) are computed from values/shares ordered in nondecreasing order.
To compute the Concentration measures, the R code uses several functions from the ineq library: entropy, conc, Gini, RS (the Ricci-Schutz or Pietra index; Pietra (1915)), Atkinson(Atkinson 1970), Kolm, and var.coeff. The Theil entropy index (Theil 1967) is also computed. Note that some functions have a parameter which eliminates missing data before the actual computation takes place: na.rm = T. It is generally speaking, a good idea to set this parameter to T (or TRUE). If, however, this parameter is not available, one might also use the command x = na.omit(x) before any computation takes place.
68.10 Purpose
Concentration measures are used for a wide variety of purposes. For instance, in Economics it is used to study income/wealth inequality, and in Biology it has been employed as a statistic for biodiversity. In addition, Concentration measures are often used in other types of statistical analysis such as machine learning algorithms.
Gini, Corrado. 1912. “Variabilità e Mutabilità.”Studi Economico-Giuridici Della Facoltà Di Giurisprudenza Dell’Università Di Cagliari 3: 3–159.
Herfindahl, Orris C. 1950. “Concentration in the u.s. Steel Industry.” PhD thesis, Columbia University.
Lorenz, Max O. 1905. “Methods of Measuring the Concentration of Wealth.”Publications of the American Statistical Association 9 (70): 209–19. https://doi.org/10.2307/2276207.
Pietra, Gaetano. 1915. “Delle Relazioni Tra Gli Indici Di Variabilità.”Atti Del Reale Istituto Veneto Di Scienze, Lettere Ed Arti 74: 775–804.