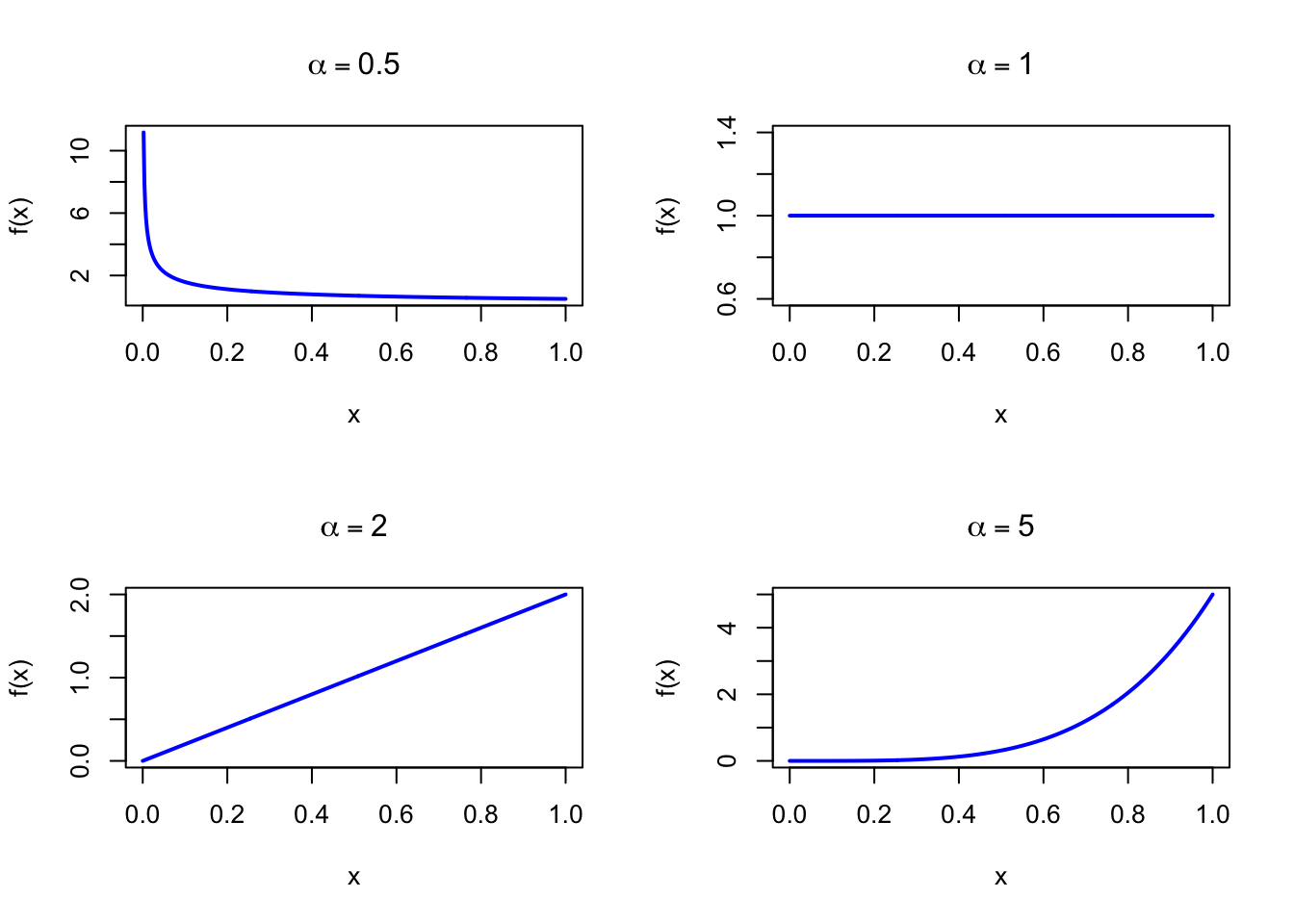
The Power distribution is a one-parameter family on \([0,1]\) that generalizes the Uniform distribution. A single shape parameter tilts the density toward 0 (for \(\alpha < 1\)) or toward 1 (for \(\alpha > 1\)), making it useful for bounded quantities with a directional preference.
Formally, the random variate \(X\) defined for the range \(X \in [0, 1]\), is said to have a Power Distribution (i.e. \(X \sim \text{Power}(\alpha)\)) with shape parameter \(\alpha > 0\). The Power distribution is equivalent to Beta\((\alpha, 1)\).
The figure below shows examples of the Power Probability Density Function for different shape values.
Code
par(mfrow =c(2, 2))x <-seq(0, 1, length =500)plot(x, dbeta(x, shape1 =0.5, shape2 =1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(alpha ==0.5))plot(x, dbeta(x, shape1 =1, shape2 =1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(alpha ==1))plot(x, dbeta(x, shape1 =2, shape2 =1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(alpha ==2))plot(x, dbeta(x, shape1 =5, shape2 =1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(alpha ==5))par(mfrow =c(1, 1))
Figure 41.1: Power Probability Density Function for various shape values
41.2 Purpose
The Power distribution models bounded quantities in \([0,1]\) when the density is monotone — either increasing or decreasing — rather than bell-shaped. Its single parameter determines whether small values (near 0) or large values (near 1) are most likely. Common applications include:
Proportion of correct answers when most respondents score high or low
Reliability: proportion of items surviving a stress test when failure is rare or common
Revenue share distributions: when one party captures most of the total
Prior distribution for probabilities biased toward extreme values
Order statistics from the Uniform distribution on \([0,1]\)
Relation to the discrete setting. Power\((\alpha)\) = Beta\((\alpha, 1)\) is a continuous model for proportions; its discrete analog is the Bernoulli distribution (for a single bounded outcome) or a Discrete Uniform (when \(\alpha = 1\)). For integer-valued bounded counts, the Binomial plays a similar role.
41.3 Distribution Function
\[
F(x) = x^\alpha, \quad 0 \leq x \leq 1
\]
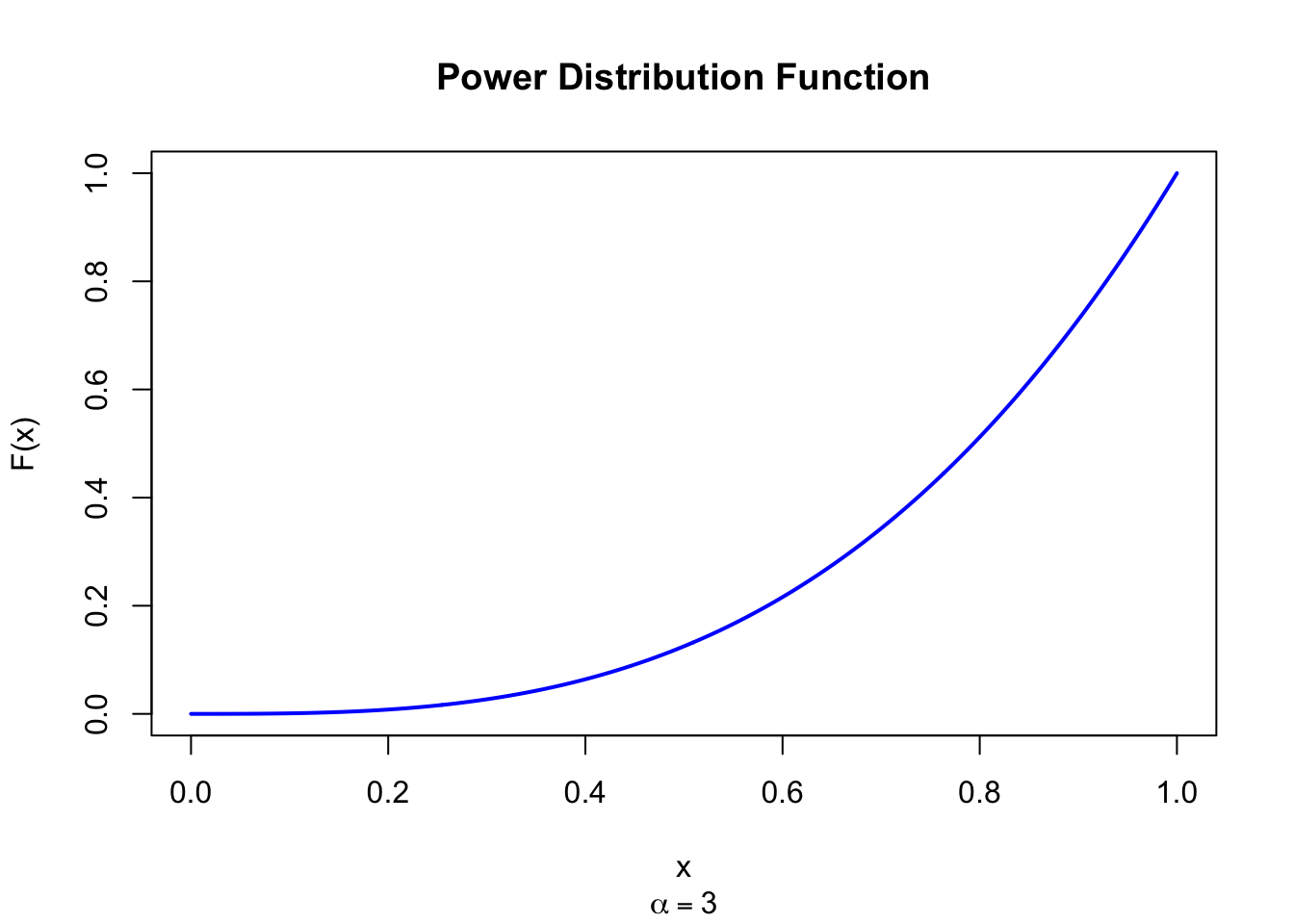
The figure below shows the Power Distribution Function for \(\alpha = 3\).
Code
x <-seq(0, 1, length =500)plot(x, pbeta(x, shape1 =3, shape2 =1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="F(x)", main ="Power Distribution Function",sub =expression(alpha ==3))
Figure 41.2: Power Distribution Function (alpha = 3)
41.4 Moment Generating Function
The MGF has no simple closed form. Raw moments are computed directly:
The proportion of correct answers on a test is modeled as \(X \sim \text{Power}(3)\). This implies the density is \(f(x) = 3x^2\), concentrated toward high scores. The mean proportion is \(3/4 = 0.75\).
The MLE \(\hat\alpha = -n/\sum \ln x_i\) is one of the few analytically tractable maximum likelihood estimators in the Beta family, but it is biased for \(n > 1\). For \(n > 1\), the UMVUE is \(\hat\alpha_U = (n-1)/(-\sum \ln x_i)\).
41.25 Related Distributions 1: Beta Distribution
The Power distribution is the Beta\((\alpha, 1)\) special case (see Chapter 30).
41.26 Related Distributions 2: Uniform Distribution
The Uniform distribution is Power\((1)\) (see Chapter 19).