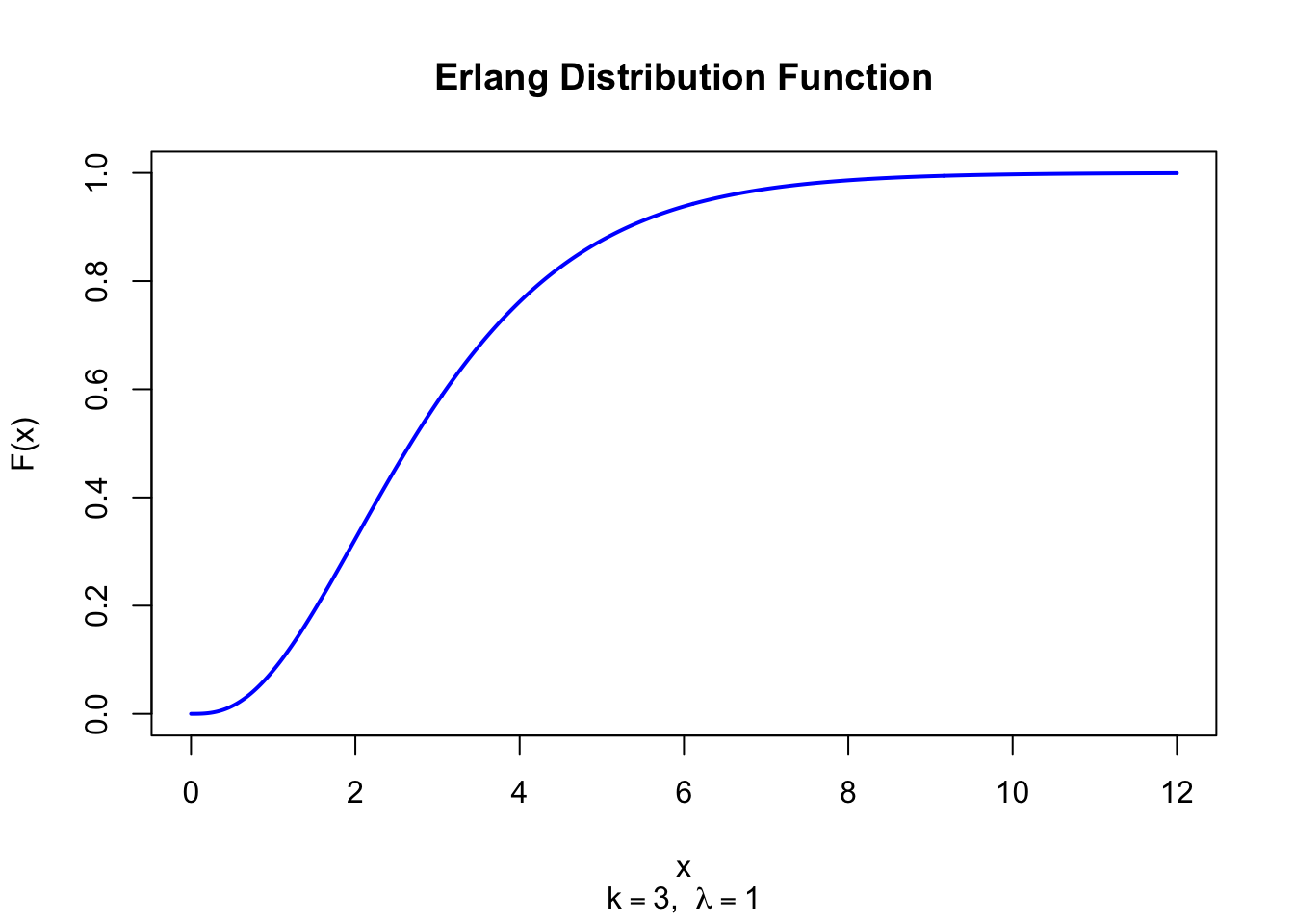
The Erlang distribution is the Gamma distribution restricted to positive-integer shape parameters. Developed by A.K. Erlang for telephone traffic engineering, it models the accumulated waiting time across exactly \(k\) independent exponential stages — the standard model for multi-phase service times in queuing systems.
Formally, the random variate \(X\) defined for the range \(X > 0\), is said to have an Erlang Distribution (i.e. \(X \sim \text{Erlang}(k, \lambda)\)) with positive-integer shape \(k \geq 1\) and rate parameter \(\lambda > 0\). The Erlang\((k, \lambda)\) distribution equals the Gamma\((k, \lambda)\) distribution when \(k\) is a positive integer. In R, use dgamma(x, shape = k, rate = lambda) with integer shape.
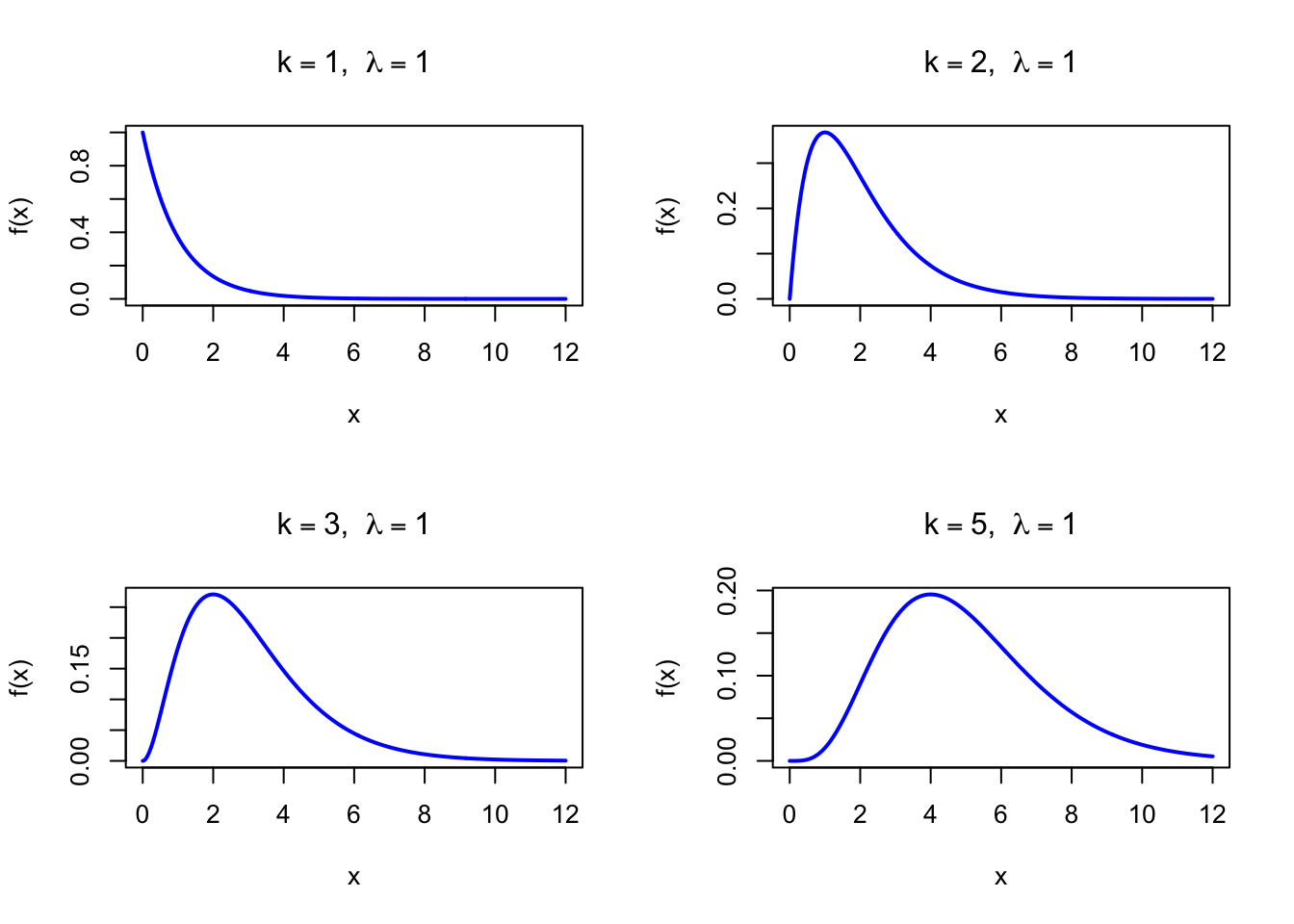
The figure below shows examples of the Erlang Probability Density Function for different shape values with \(\lambda = 1\).
Code
par(mfrow =c(2, 2))x <-seq(0, 12, length =500)plot(x, dgamma(x, shape =1, rate =1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(paste(k ==1, ", ", lambda ==1)))plot(x, dgamma(x, shape =2, rate =1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(paste(k ==2, ", ", lambda ==1)))plot(x, dgamma(x, shape =3, rate =1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(paste(k ==3, ", ", lambda ==1)))plot(x, dgamma(x, shape =5, rate =1), type ="l", lwd =2, col ="blue",xlab ="x", ylab ="f(x)", main =expression(paste(k ==5, ", ", lambda ==1)))par(mfrow =c(1, 1))
Figure 35.1: Erlang Probability Density Function for various shape values (rate = 1)
35.2 Purpose
The Erlang distribution was developed to model the total waiting time across a fixed number of exponential service stages in telephone switching systems. Its requirement of a positive-integer shape parameter makes it more interpretable than the Gamma distribution in queuing contexts: \(k\) is a literal count of stages. Common applications include:
Multi-stage service times in call centers and telecommunications networks
Total processing time across sequential stages in manufacturing
Aggregate customer service duration when each interaction has \(k\) steps
Waiting time before the \(k\)-th arrival in a Poisson process
Hypo-exponential distribution building block (sum of different Exponentials)
Relation to the discrete setting. The Erlang distribution is the continuous analog of the Negative Binomial distribution — the Negative Binomial counts discrete failures before the \(k\)-th success; the Erlang measures continuous total time until the \(k\)-th Poisson event.
A call center requires customers to complete \(k = 3\) sequential service stages, each with an independent Exponential service time at rate \(\lambda = 2\) per minute. Total service time \(X \sim \text{Erlang}(3, 2)\) has mean \(k/\lambda = 1.5\) minutes.
35.22 Property 1: Special Case of Gamma with Integer Shape
The Erlang\((k, \lambda)\) distribution is identical to the Gamma\((k, \lambda)\) distribution when \(k\) is a positive integer. The Gamma distribution allows non-integer shapes (see Chapter 29).
35.23 Property 2: Sum of Independent Exponentials
If \(X_1, \ldots, X_k \overset{\text{i.i.d.}}{\sim} \text{Exp}(\lambda)\) then: