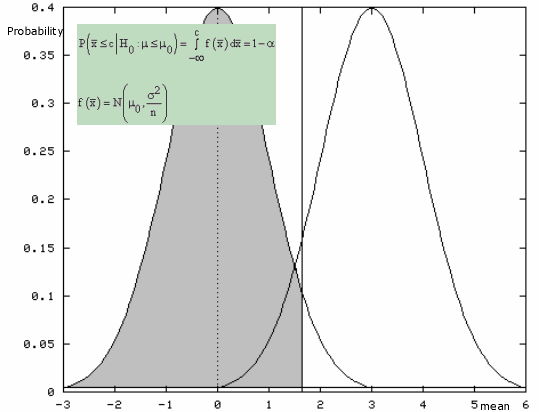
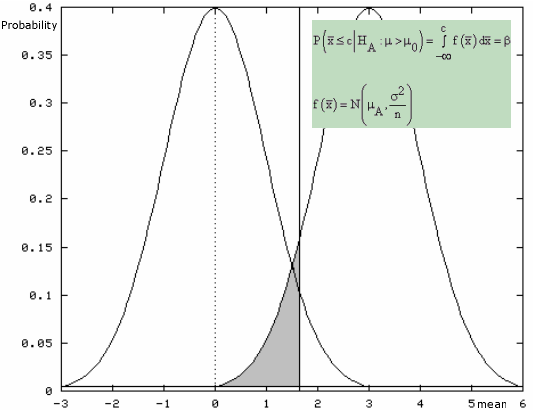
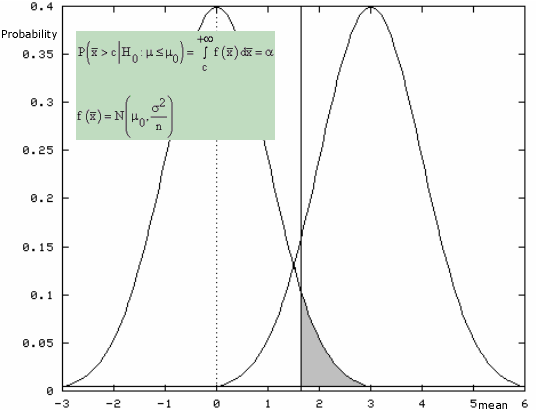
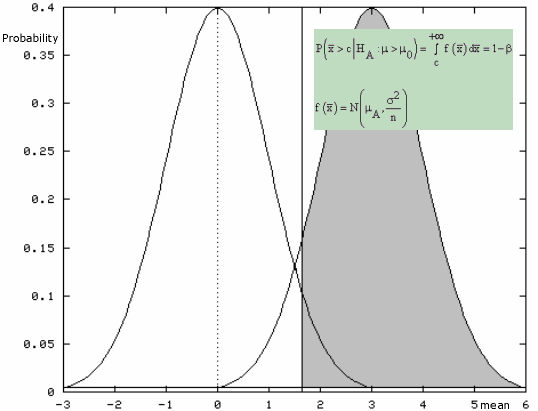
Mathematical Solution
\[
\text{P} \left( \bar{x} \geq c \| \text{H}_0: \mu = \mu_0 \right) = \alpha = 0.05
\]
\[
\text{P} \left( \bar{x} \geq c \| \text{H}_0: \mu = \mu_0 \right) = \intop_c^{\infty} \text{f} \left( \bar{x} \| \text{H}_0: \mu = \mu_0 \right) \text{d} \bar{x} = \alpha = 0.05
\]
where
\[
\text{f} \left( \bar{x} \| \text{H}_0: \mu = \mu_0 \right) = \frac{ \sqrt{n} }{ \sigma \sqrt{2 \pi} } e ^ { -\frac{n \left( \bar{x} - \mu_0 \right)^2 }{2 \sigma^2} } = \frac{1}{ \frac{\sigma}{\sqrt{n} } \sqrt{2 \pi} } e ^ { -\frac{ \left( \bar{x} - \mu_0 \right)^2 }{2 \frac{\sigma^2}{n} } }
\]
Hence,
\[
\text{P} \left( \bar{x} \geq c \| \text{H}_0: \mu = \mu_0 \right) = \frac{\sqrt{n}}{\sigma \sqrt{2 \pi} } \intop_c^{\infty} e ^ { - \frac{n \left( \bar{x} - \mu_0 \right)^2 }{2 \sigma^2} } \text{d} \bar{x}
\]
\[
\text{P} \left( \bar{x} \geq c \| \text{H}_0: \mu = \mu_0 \right) = \frac{1}{ \frac{\sigma}{\sqrt{n}} \sqrt{2 \pi} } \intop_c^{\infty} e ^ { - \frac{ \left( \bar{x} - \mu_0 \right)^2 }{2 \frac{\sigma^2}{n} } } \text{d} \bar{x} = \alpha = 0.05
\]
If we define
\[
u = \frac{ \bar{x} - \mu_0 }{\frac{\sigma}{\sqrt{n} } }
\]
then it follows that
\[
u \sim \text{N} \left( 0, 1 \right)
\]
\[
\text{P} \left( \frac{\bar{x} - \mu_0 }{\frac{\sigma}{\sqrt{n} } } \geq \frac{c - \mu_0 } {\frac{\sigma } {\sqrt{n} } } \right) = \alpha = 0.05
\]
\[
P\left( u \geq 1.645 \right) = \alpha = 0.05
\]
Hence,
\[
\text{P} \left(u \geq 1.645 \right) = \intop_{1.645}^{\infty} \text{f}(u)\text{d}u = \frac{1 } {\sqrt{2 \pi} } \intop_{1.645}^{\infty} e^{-\frac{u^2 } {2 } } \text{d}u = 0.05
\]
\[
\frac{c - \mu_0 } {\frac{\sigma } {\sqrt{n} } } = 1.645
\]
\[
c = \mu_0 + 1.645 \frac{\sigma } {\sqrt{n} }
\]
\[
c = 5.528971 \simeq 5.53
\]